Ryan Collins, Harrison Brand, Daniel MacArthur, and Mike Talkowski
The first gnomAD structural variant (SV) callset is now available via the gnomAD website and integrated directly into the gnomAD Browser.
This initial gnomAD SV callset includes nearly a half-million distinct SVs across seven SV mutational classes and 13 subclasses of complex SVs detected in 14,891 genomes spanning four major global populations. In the publicly released callset and gnomAD browser, you can find site, frequency, and annotation data for ~445k SVs from 10,738 unrelated genomes with appropriate consent to allow the release of this information.
In this post we summarize how we created this new call set, and some important practical considerations when using it. You can get more details, including callset generation and analyses, in the full gnomAD-SV preprint available on bioRxiv.
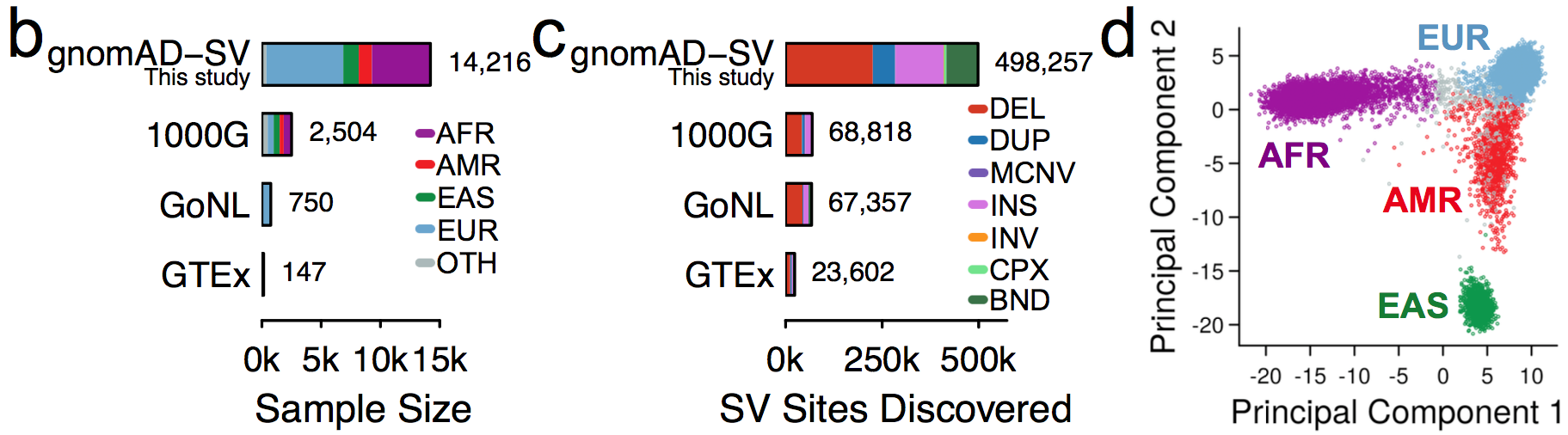
We jointly analyzed 14,891 genomes, 14,216 (95.5%) of which passed initial data quality thresholds, using a multi-algorithm consensus approach (details below) to construct the initial gnomAD SV callset. These samples were all sequenced with 150bp Illumina reads to an average coverage of 32X, and were aligned to the GRCh37/hg19 reference genome. Like previous gnomAD releases, this cohort was aggregated across various population genetic and complex disease studies, and most (57.4%) of the gnomAD-SV cohort overlaps with the genomes included in the current (v2.1) gnomAD SNV and indel callset (for more details, see the supplementary information for the gnomAD-SV preprint).
We subdivided samples into four continental populations and one “other” category, as follows:
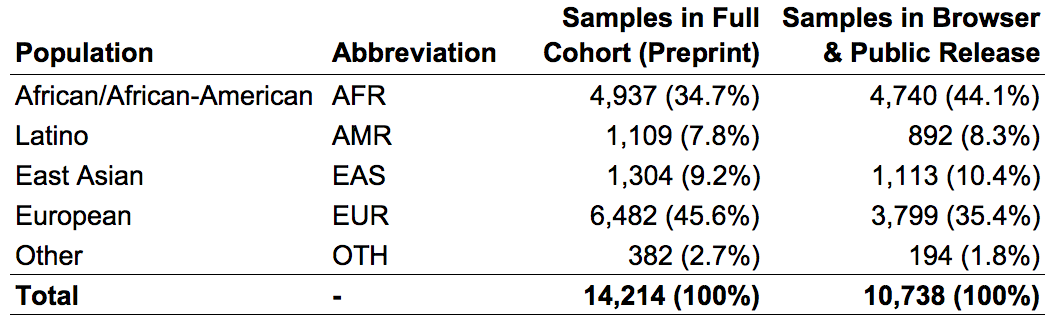
In the gnomAD Browser and the released VCF, we provide variant frequencies separately for each of the four major populations as well as the “other” category.
As with the SNV & indel callset, the subset of 10,738 genomes represented in the gnomAD browser have been screened to remove first-degree relatives and samples with documented pediatric or severe disease. Thus, the publicly available SV data from these 10,738 genomes represents a relatively diverse collection of unrelated individuals that should have rates of most severe diseases equivalent to, if not lower than, the general population.
The gnomAD SV callset
In gnomAD, our working definition of SVs includes all genomic rearrangements involving at least 50bp of DNA, which can be categorized into mutational classes based on their breakpoint signature(s) and/or changes in copy number.
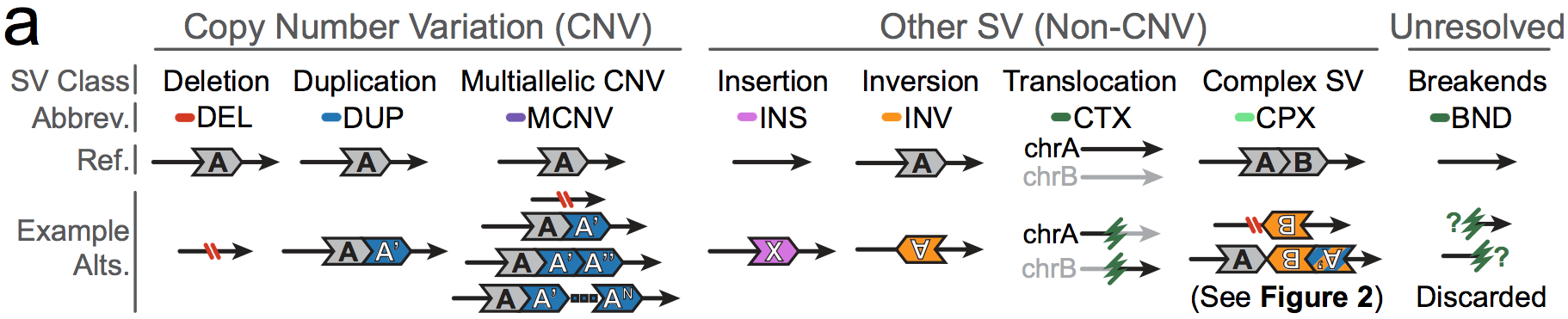
The mutational classes of SVs can be subdivided into two groups:
- Unbalanced SVs are rearrangements that result in gains or losses of genomic DNA (also known as copy number variants, or CNVs)
- Balanced SVs are rearrangements that do not involve changes in copy number
Additionally, each SV can be described as canonical or complex:
- Canonical SVs are rearrangements that involve a single distinct breakpoint signature and/or changes in copy number
- Complex SVs are rearrangements that involve two or more distinct breakpoint signatures and/or changes in copy number
Across the full gnomAD-SV dataset, we discovered a total of 498,257 distinct SVs appearing in one or more genomes, 382,460 of which (76.8%) were completely resolved and appeared in a subset of 12,549 unrelated genomes used in the formal analyses presented in the gnomAD SV preprint. We categorized SVs into the following mutational classes (note: numbers correspond to the final set of SVs from 12,549 unrelated genomes used in the gnomAD SV preprint):
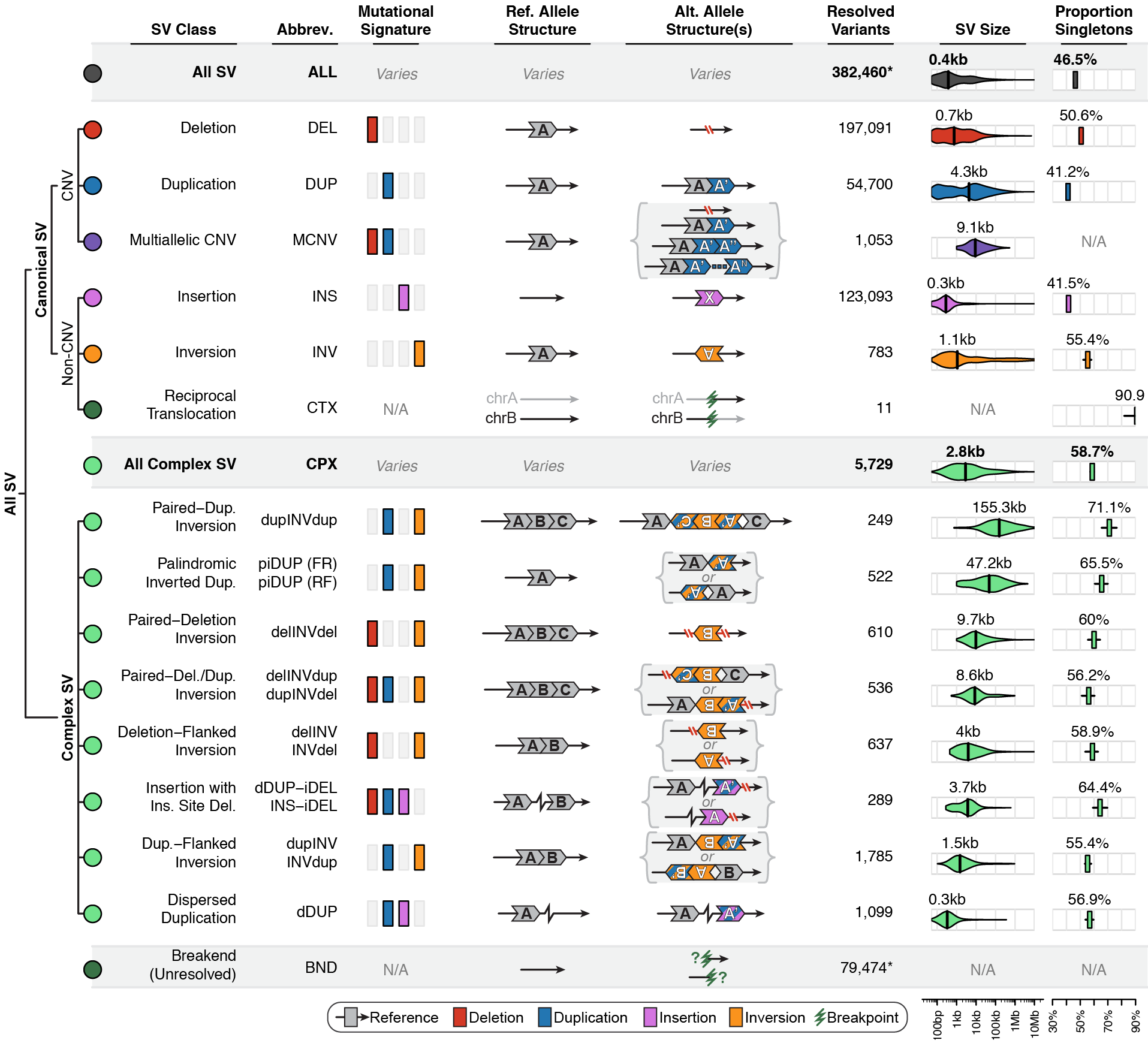
A main aim of producing this gnomAD-SV callset was to supplement existing resources by characterizing which genes in the genome are known to tolerate alteration by SVs, and specifically which kinds of rearrangement these genes can tolerate.
We annotated each SV for multiple potential genic effects using an approach described in the gnomAD SV preprint. In brief, this approach considers SV size, class, position, and overlap with exons from canonical transcripts of Gencode v19 protein-coding genes, which can be graphically summarized below for four main categories SV-gene interactions:
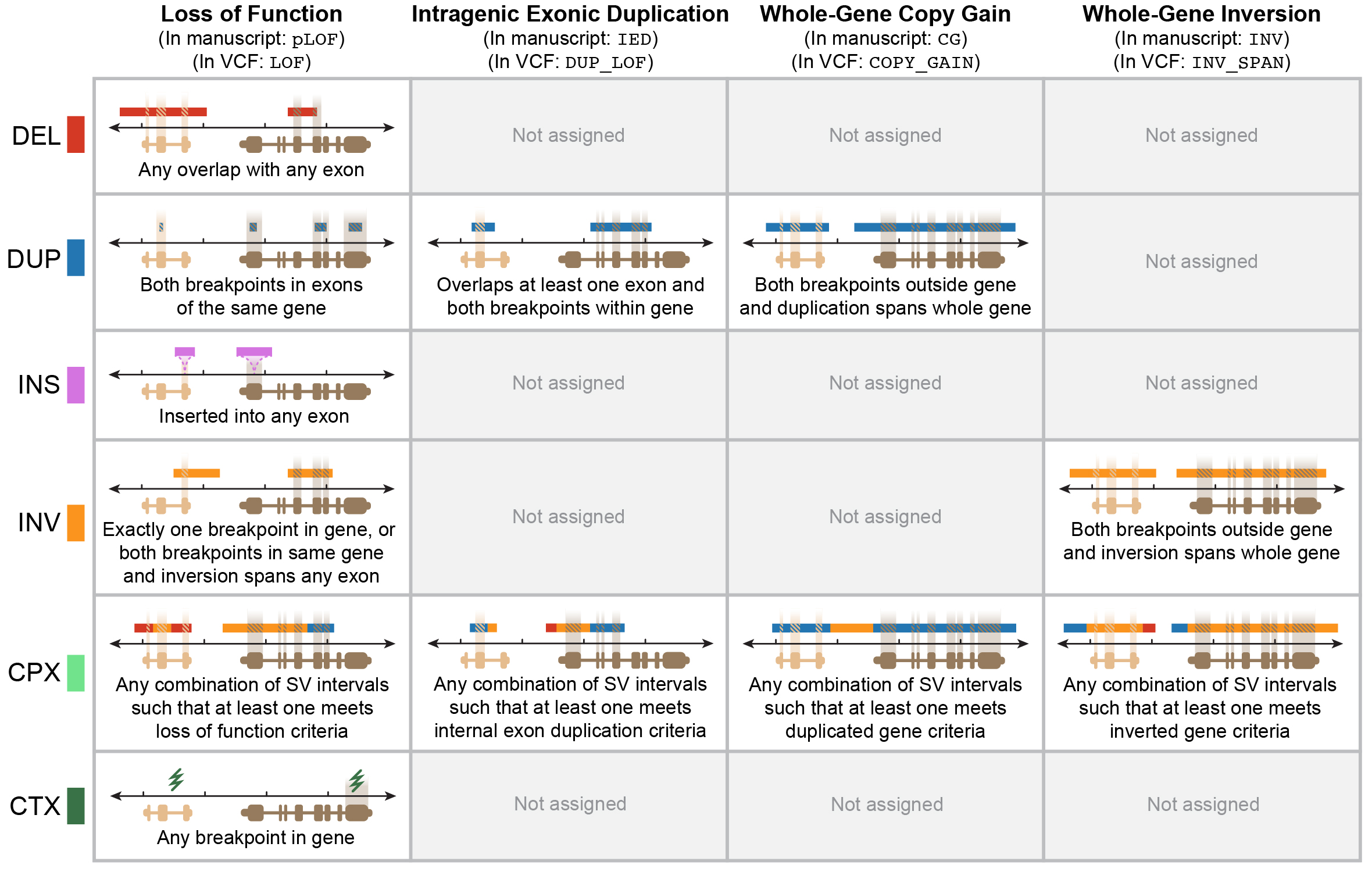
SVs in the gnomAD Browser
One of the most noteworthy aspects of the gnomAD-SV release is the direct integration of SVs into the gnomAD Browser, an effort led by the talented duo of developers, Nick Watts and Matt Solomonson.
In the near future. we intend to produce a short tutorial video covering these features. For now, you can start using the SV features right away with these two easy steps:
1. Navigate to your favorite gene or region using the search bar:

2. Select the SV dataset by clicking the toggle button in the top-right part of the screen:
Once you’ve activated SV mode in the gnomAD Browser, you can interact with the data in multiple ways, described below.
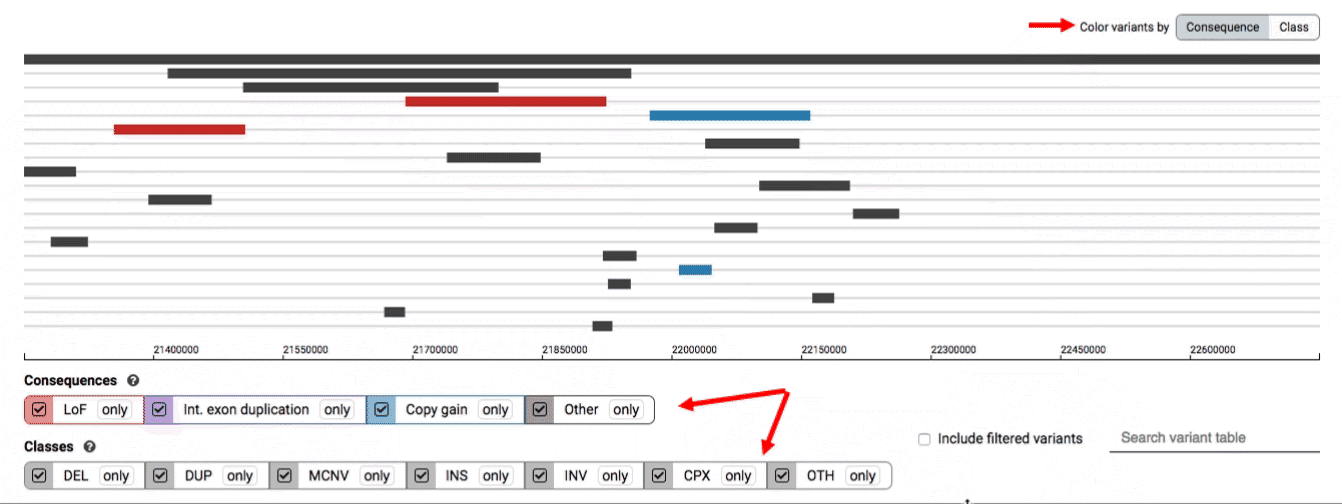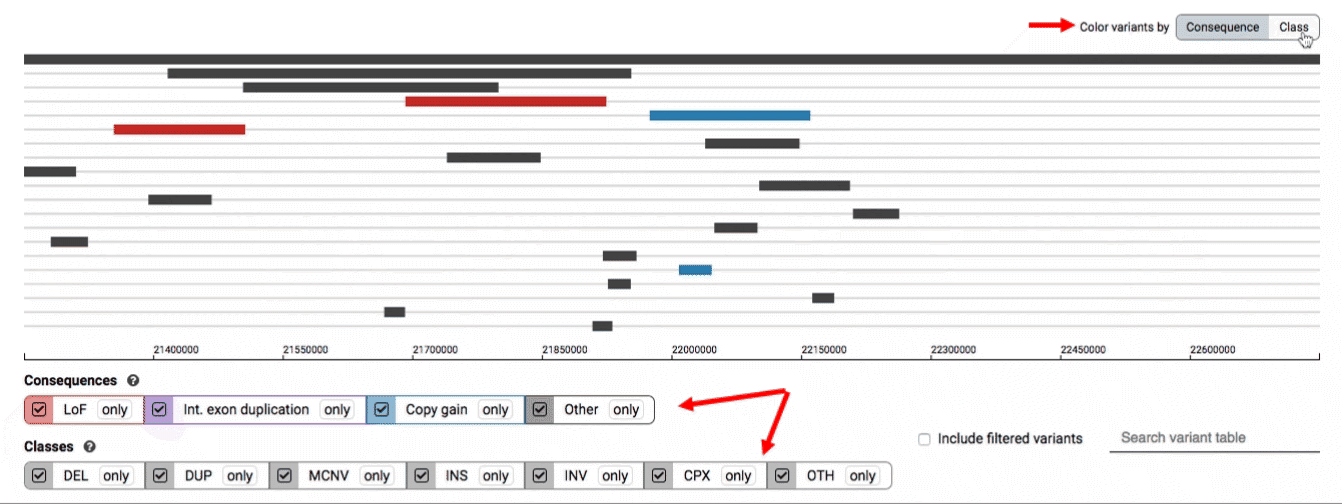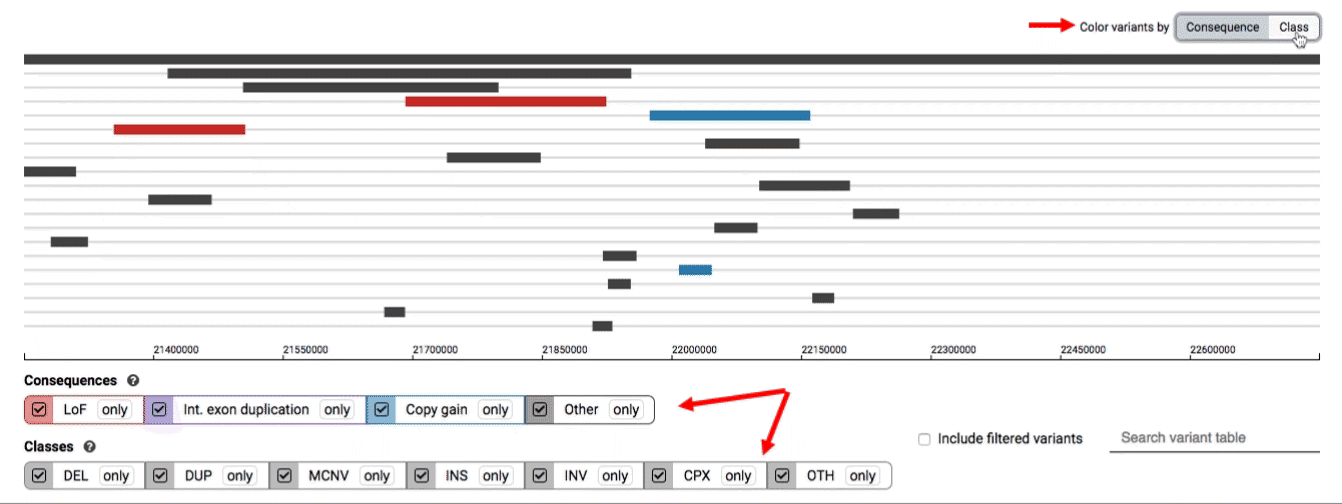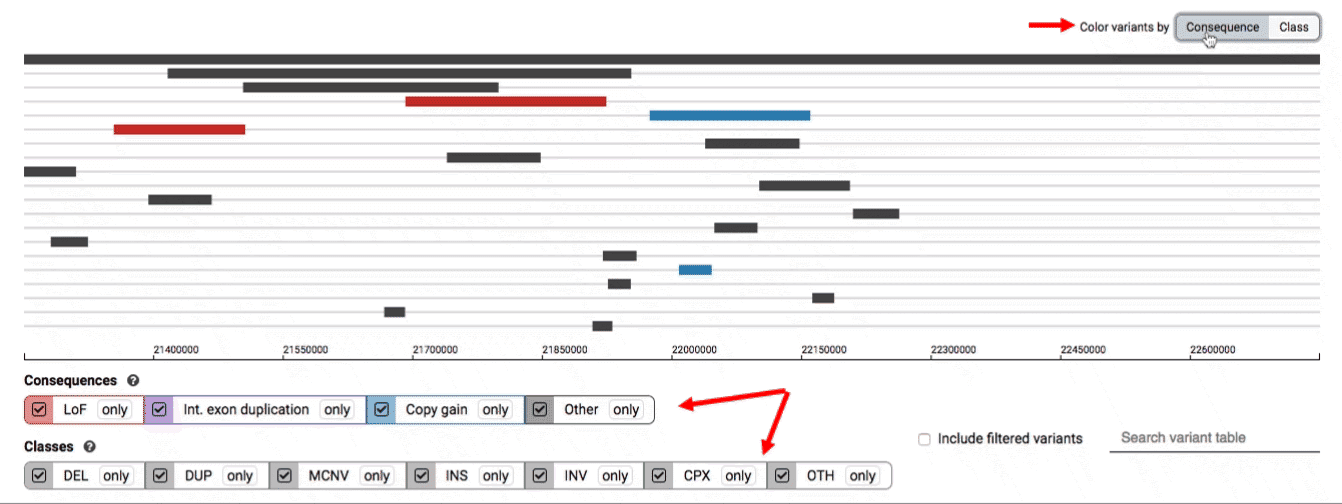
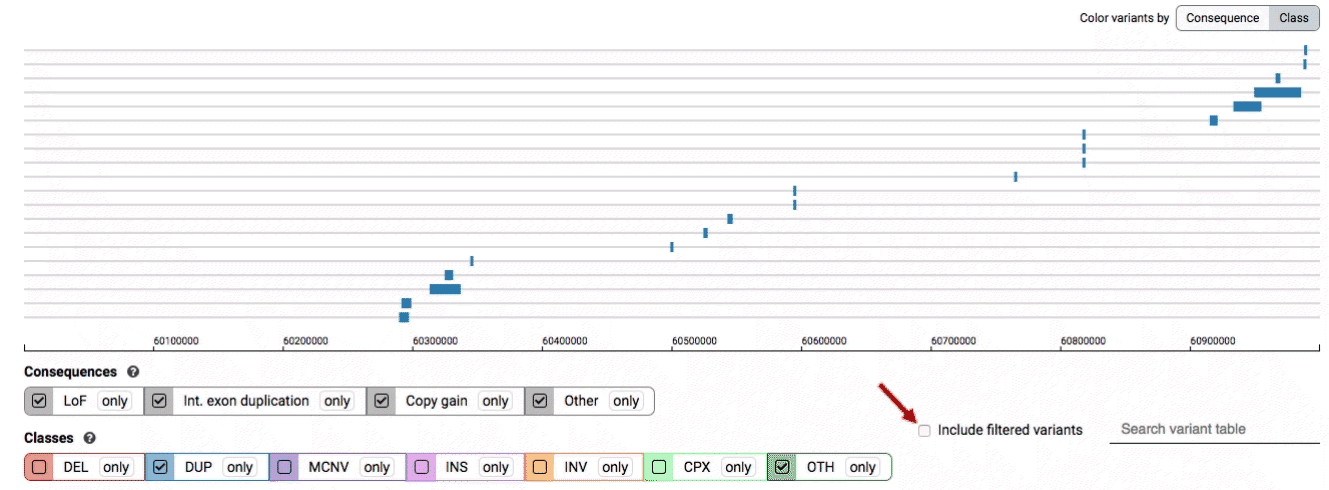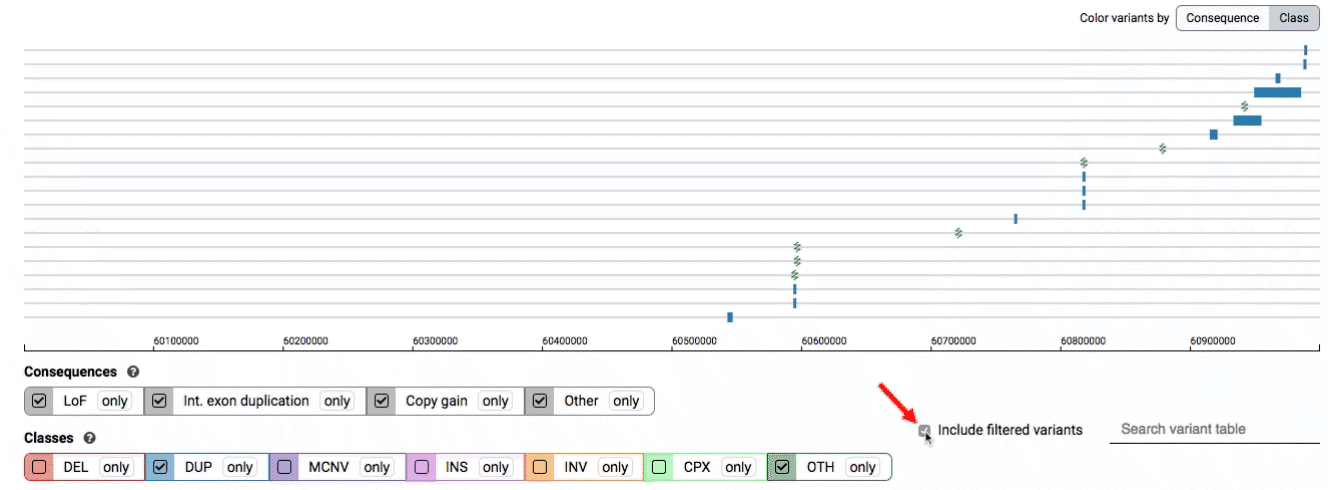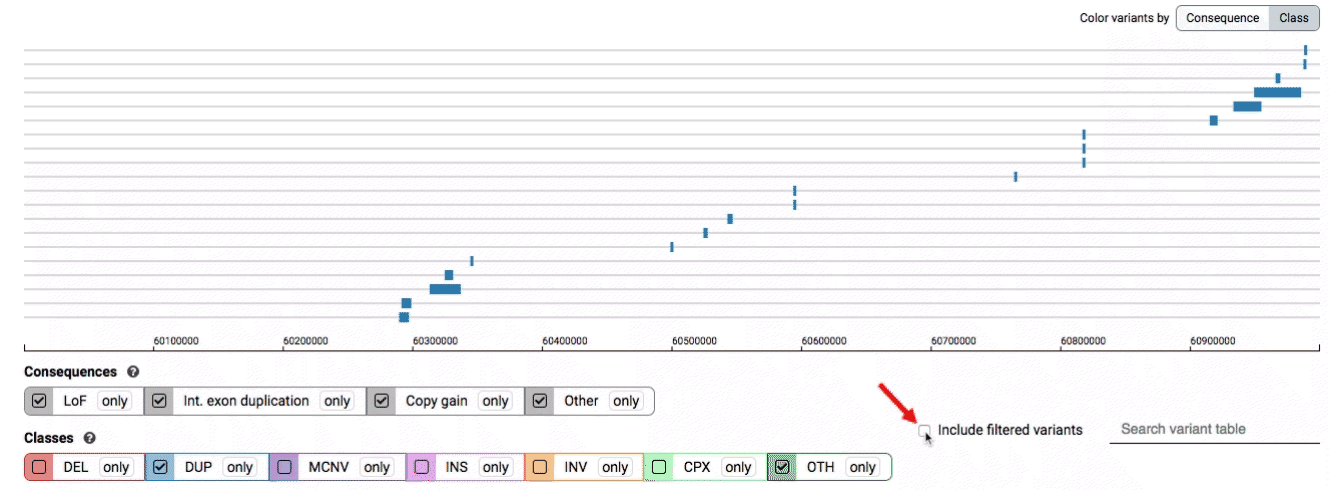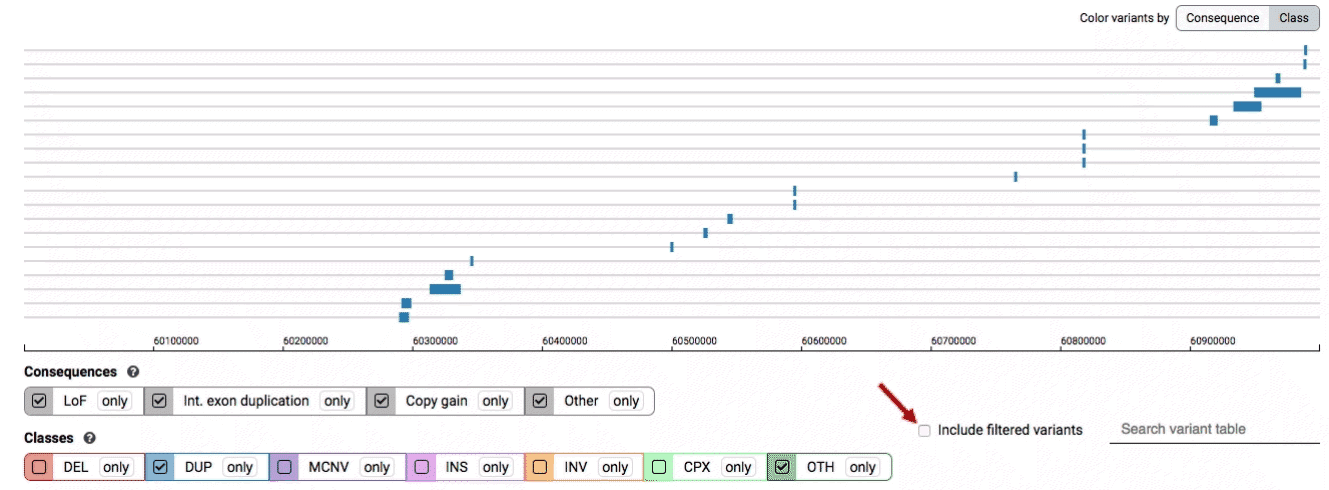
The variant track displays all SVs currently in the view range corresponding to their coordinates, with each SV on its own row.
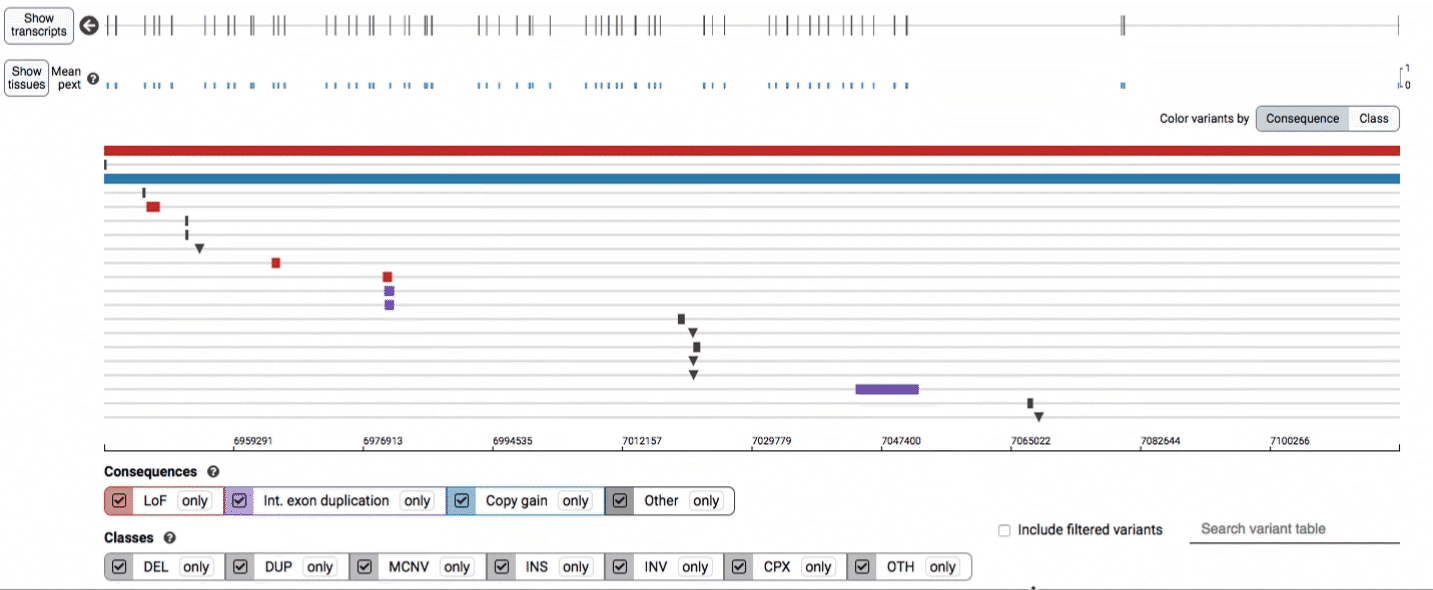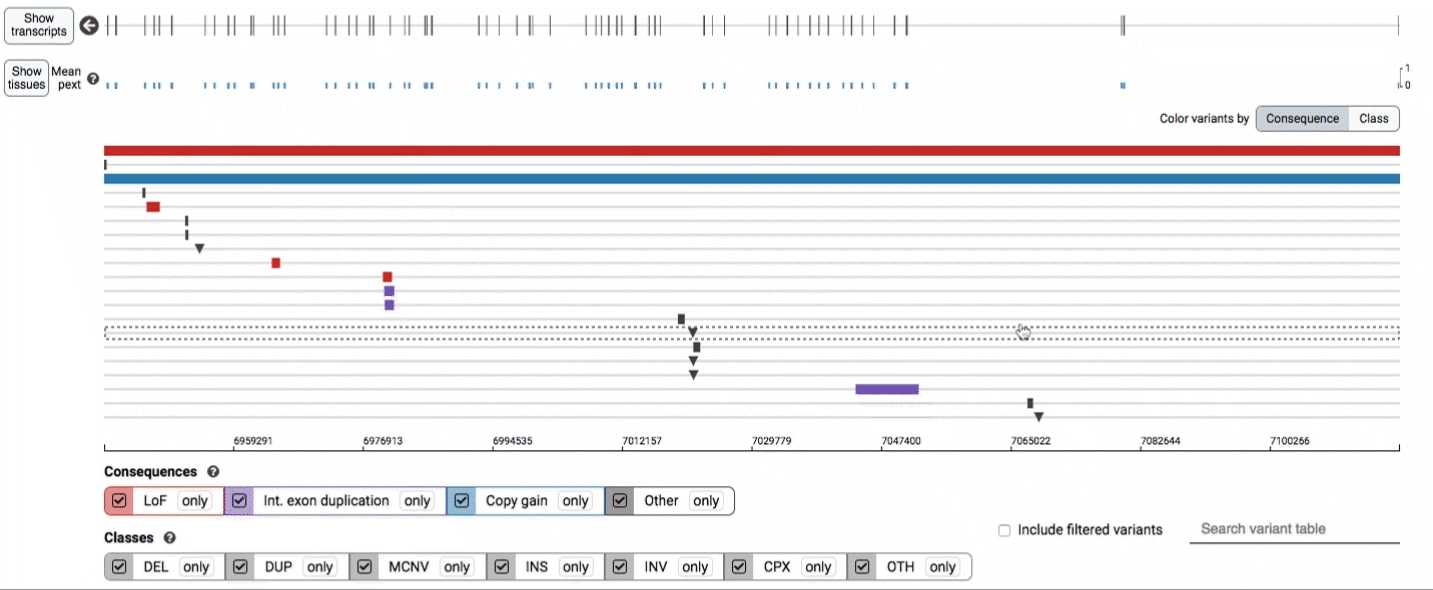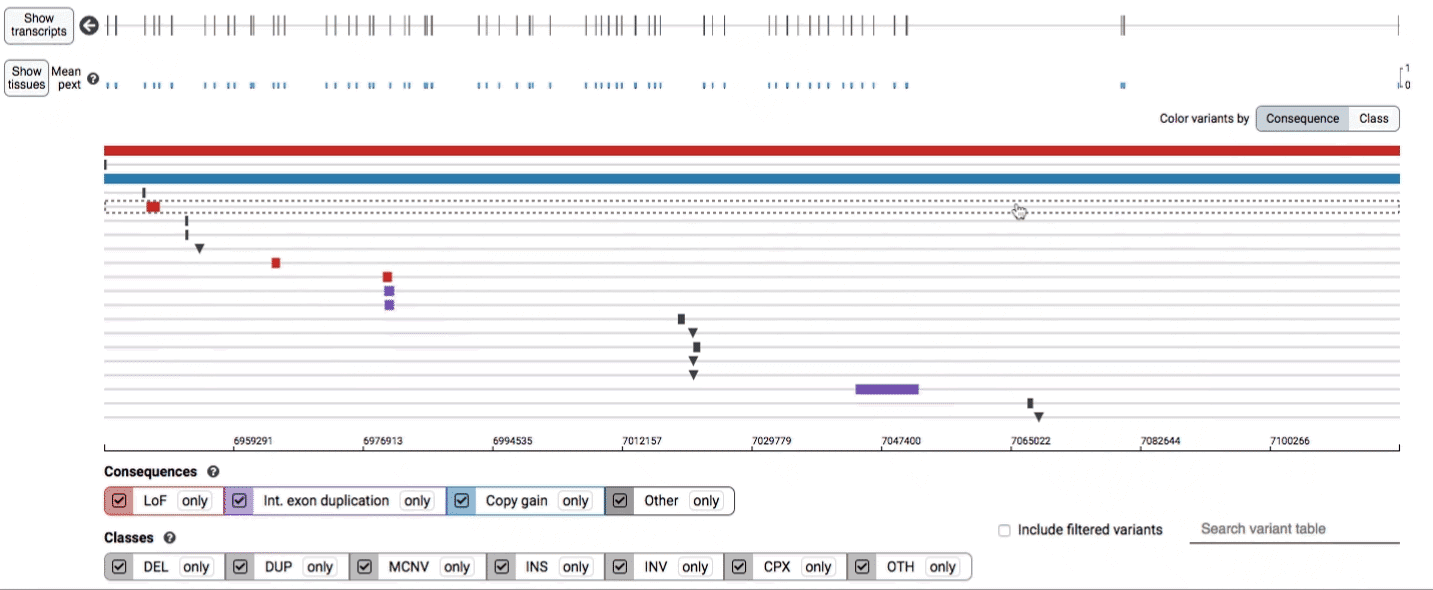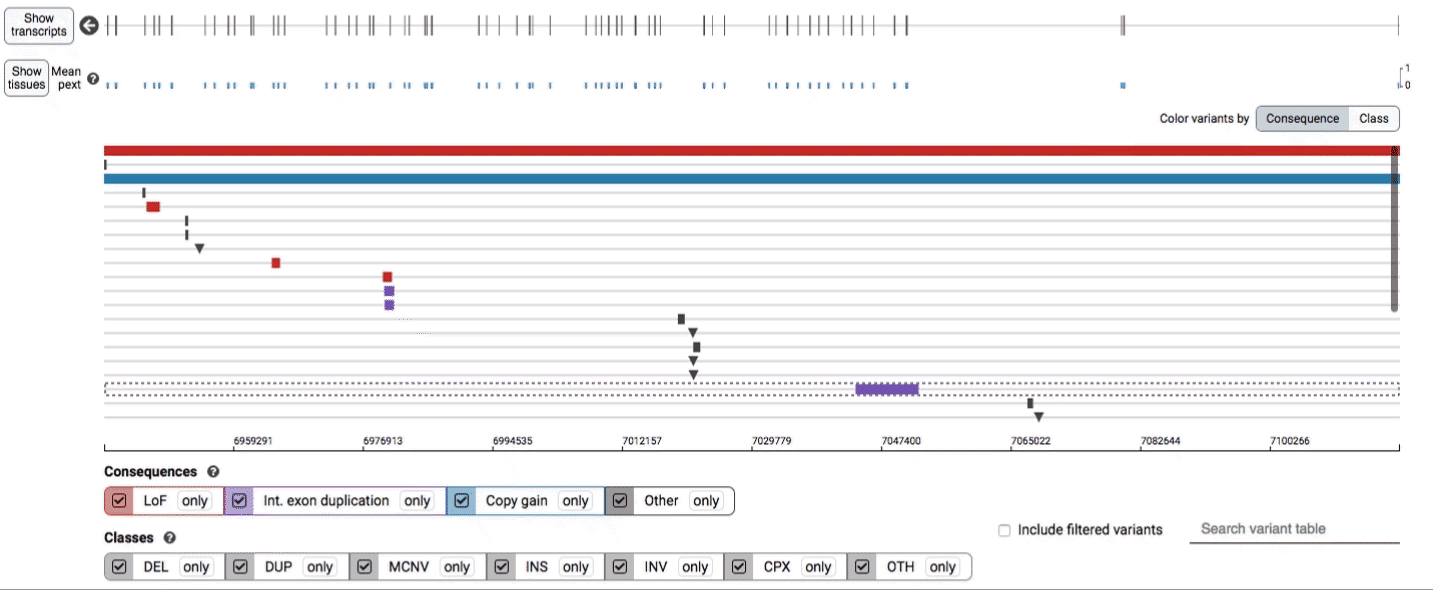
In the variant track, certain symbols are assigned to specific classes of SV, such as a triangle for insertions (denoting the position at which sequence was inserted), or a lightning bolt for breakpoints of chromosomal translocations or unresolved breakends.

The variant table provides selected metadata for each variant displayed in the variant track, including allele frequencies, consequences, number of homozygotes, coordinates, and size.

All columns in the table are sortable by clicking the column headers.
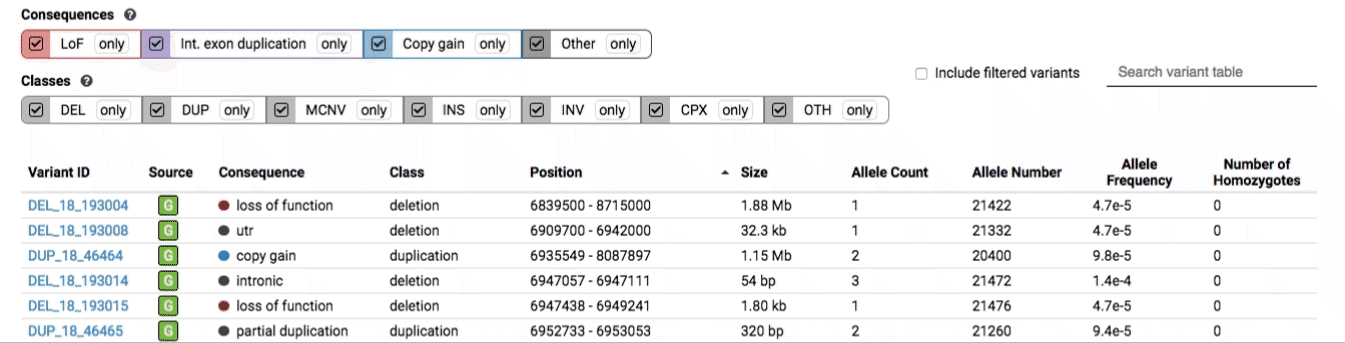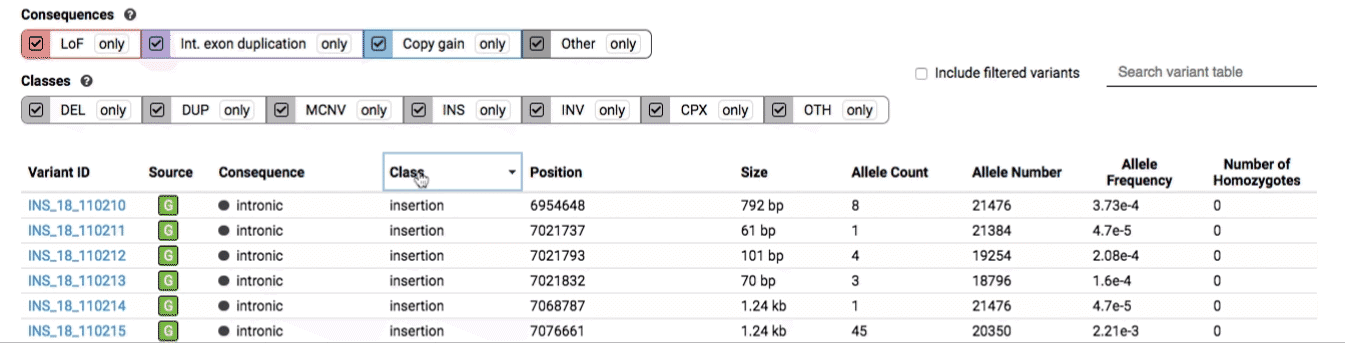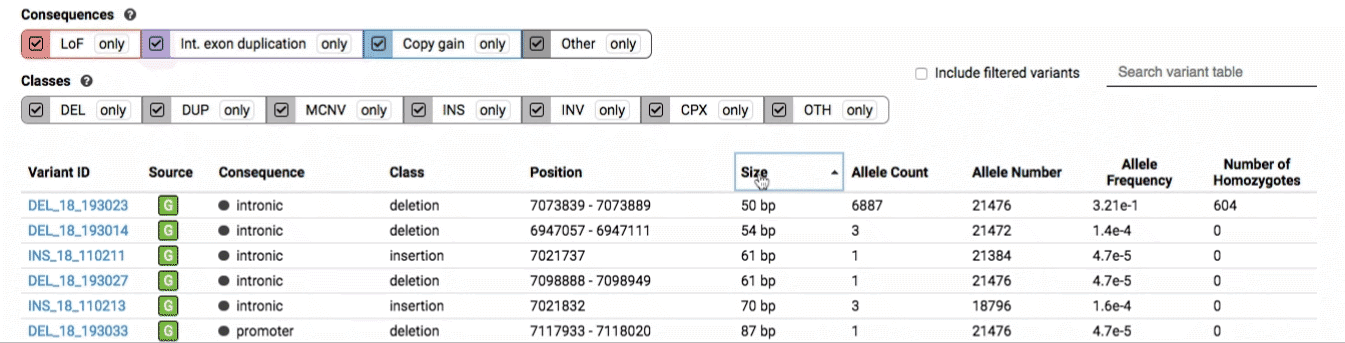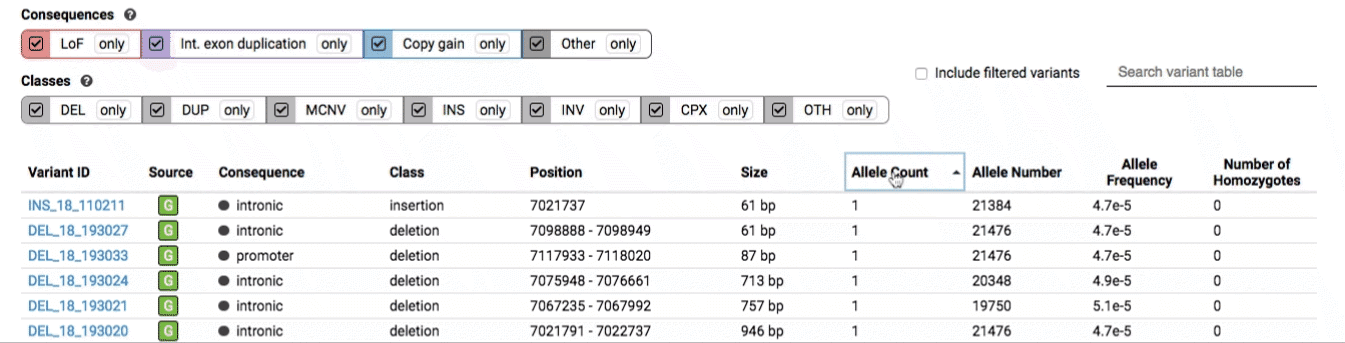
There are three main options for filtering the variant track & table:
- Filter by consequence by selecting any combination of consequences in the top row of checkboxes below the variant track
- Filter by SV class by clicking any combination of buttons in the bottom row below the variant track
- Filter by keyword by entering that keyword into the search field
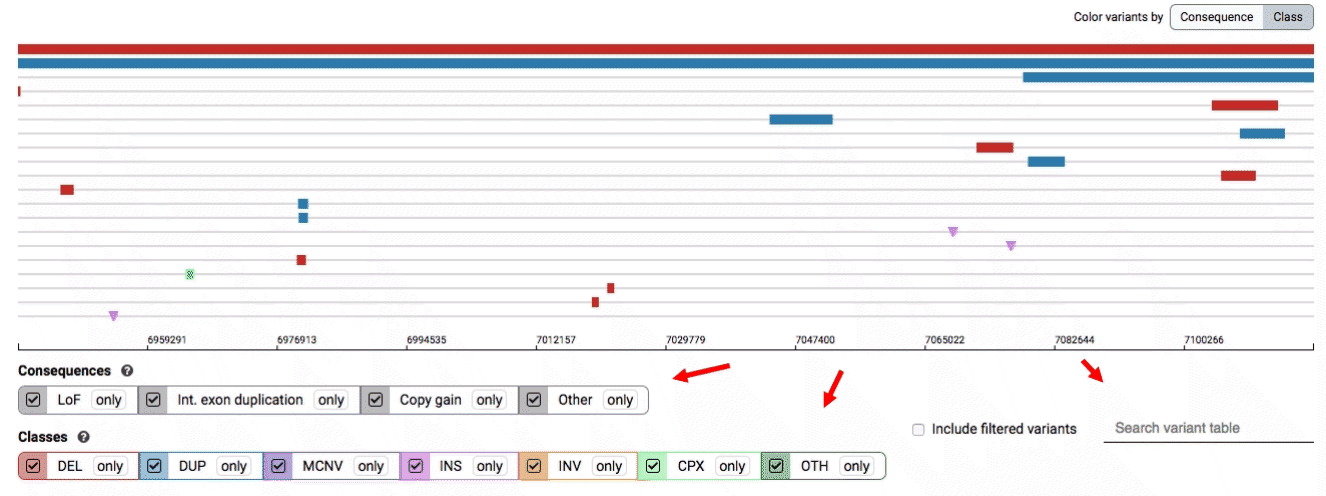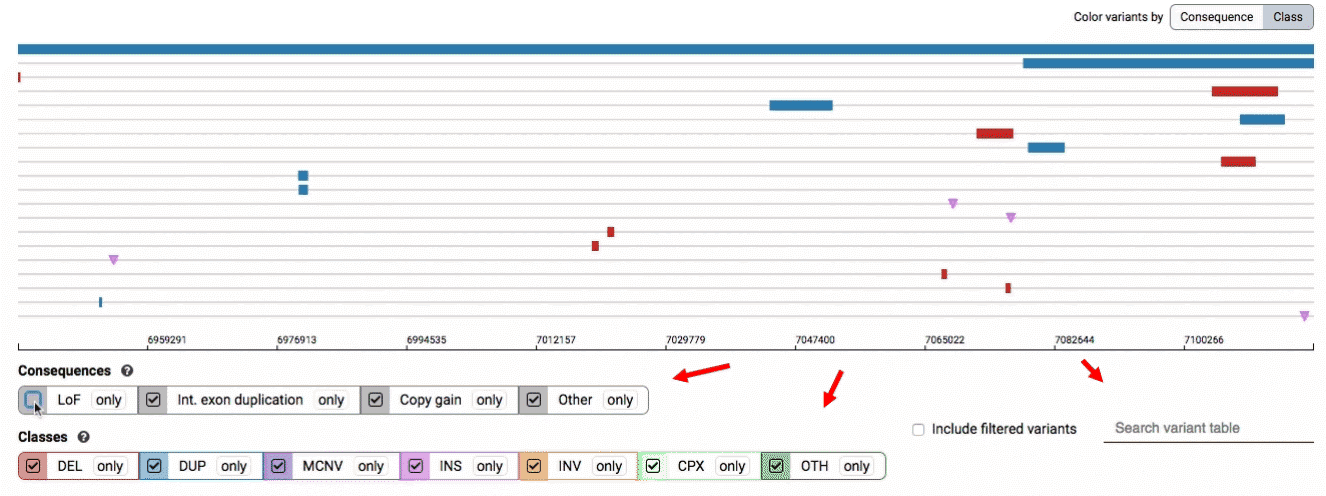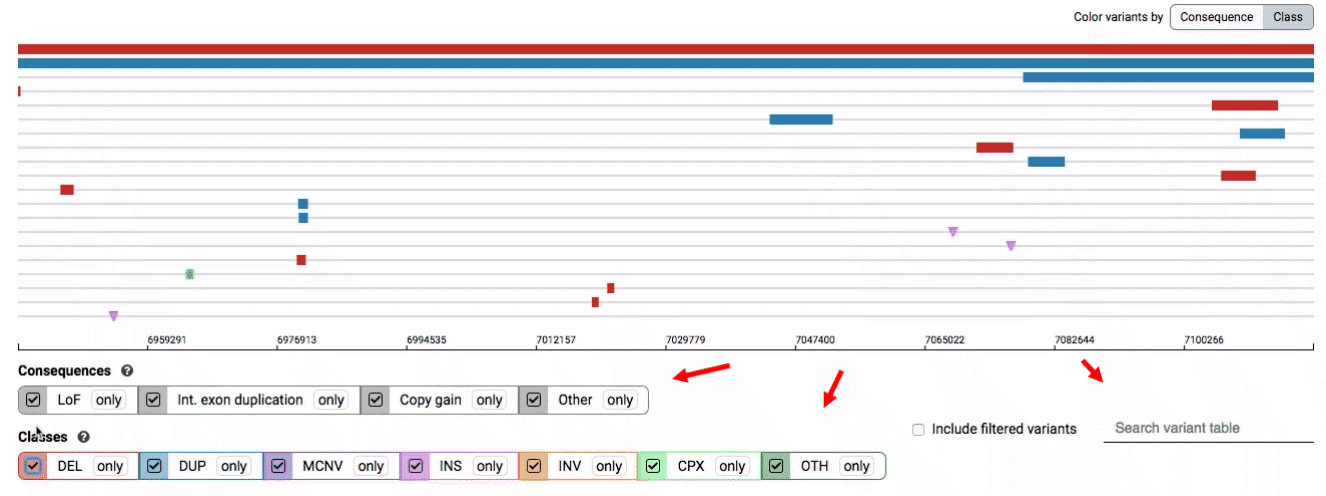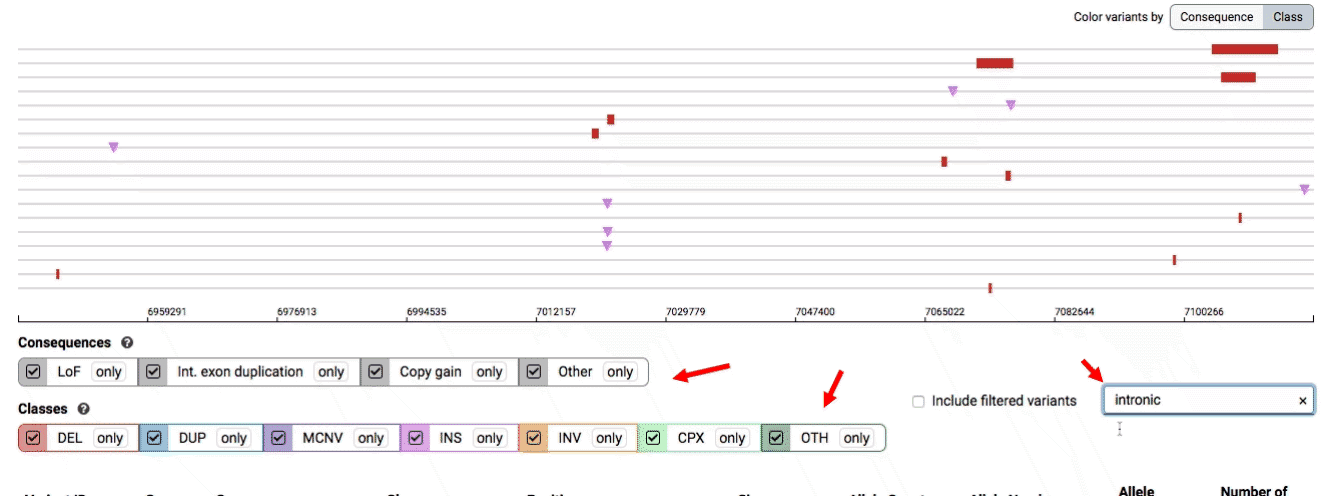
For more details about each of these filters, there are help text pop-ups available by clicking the “?” next to each row of filter buttons.
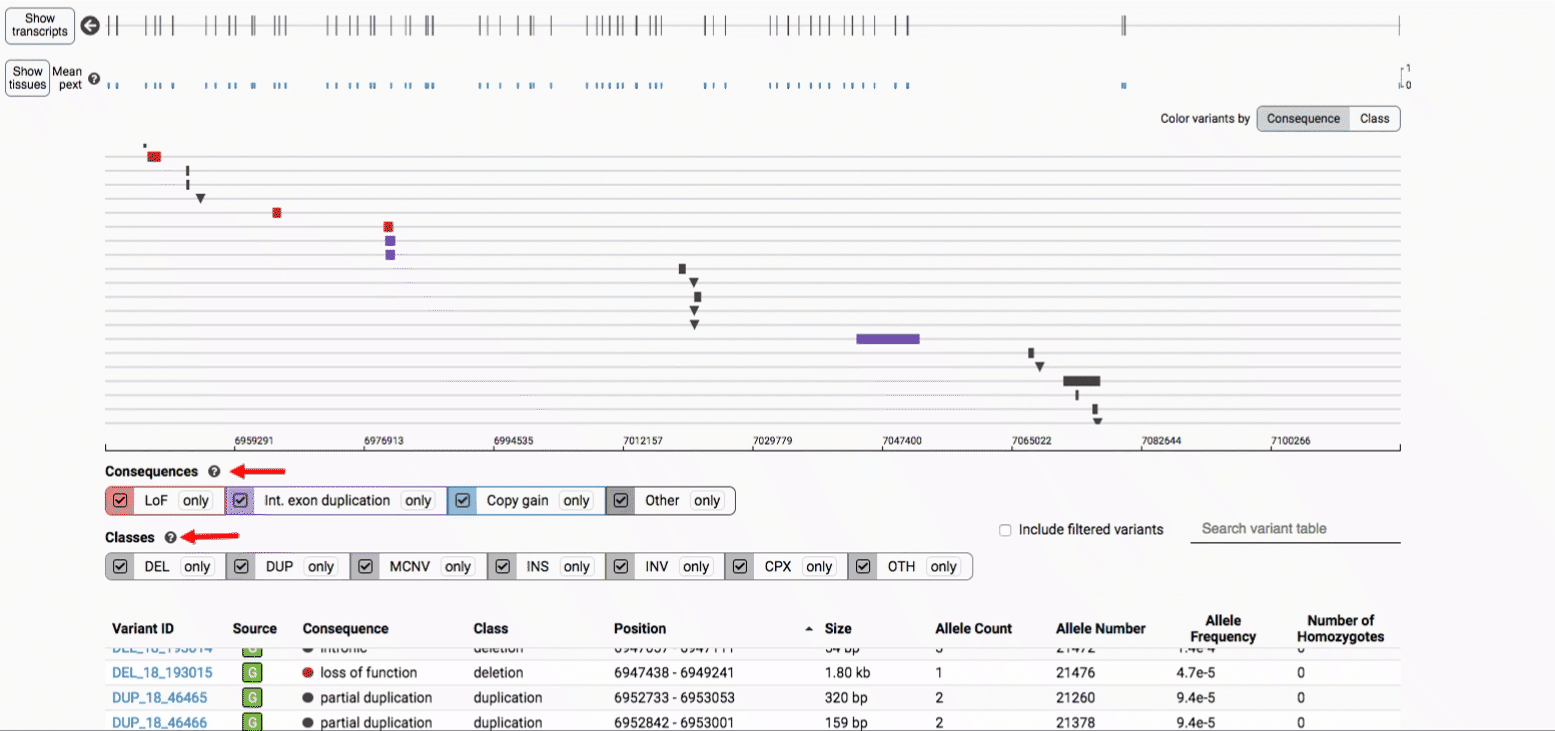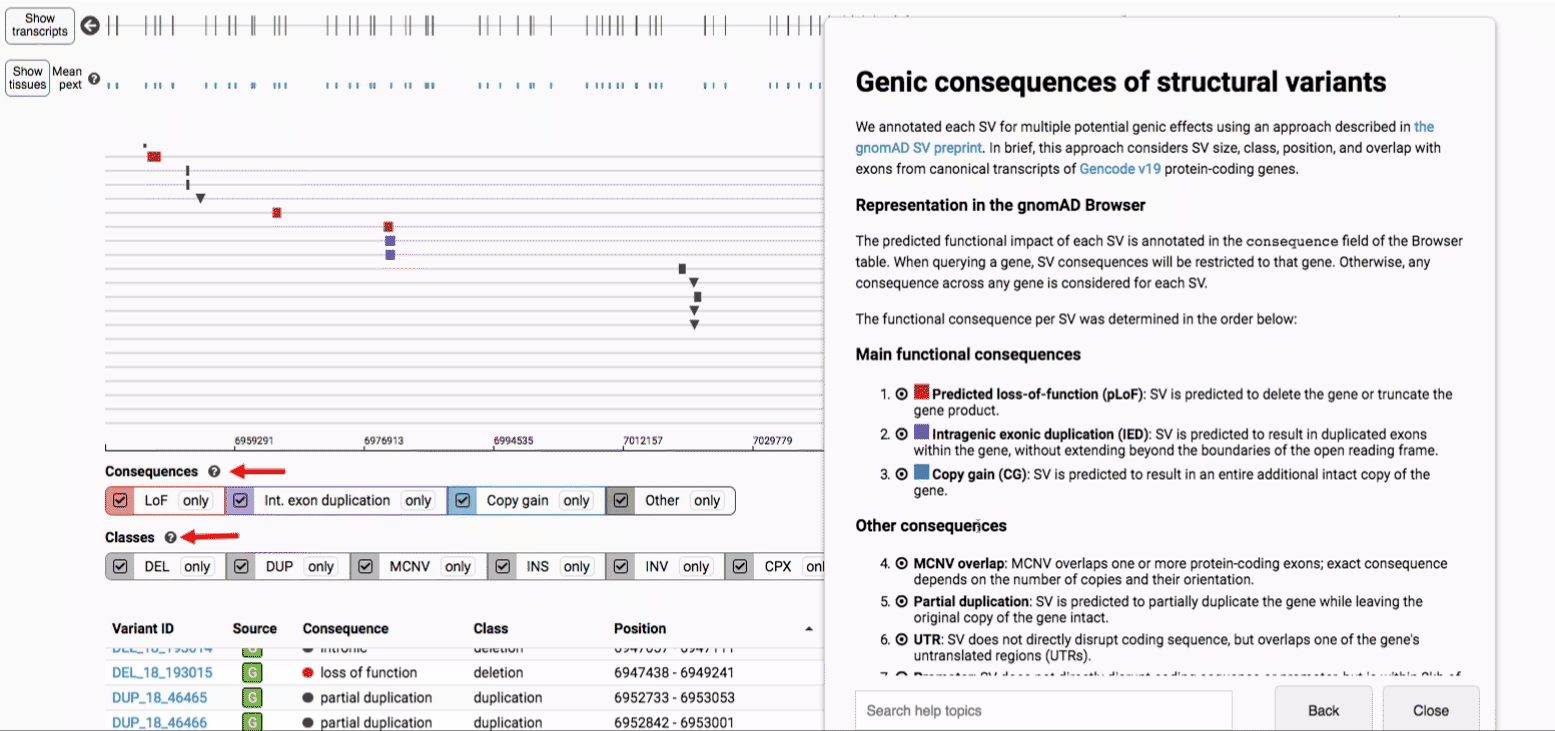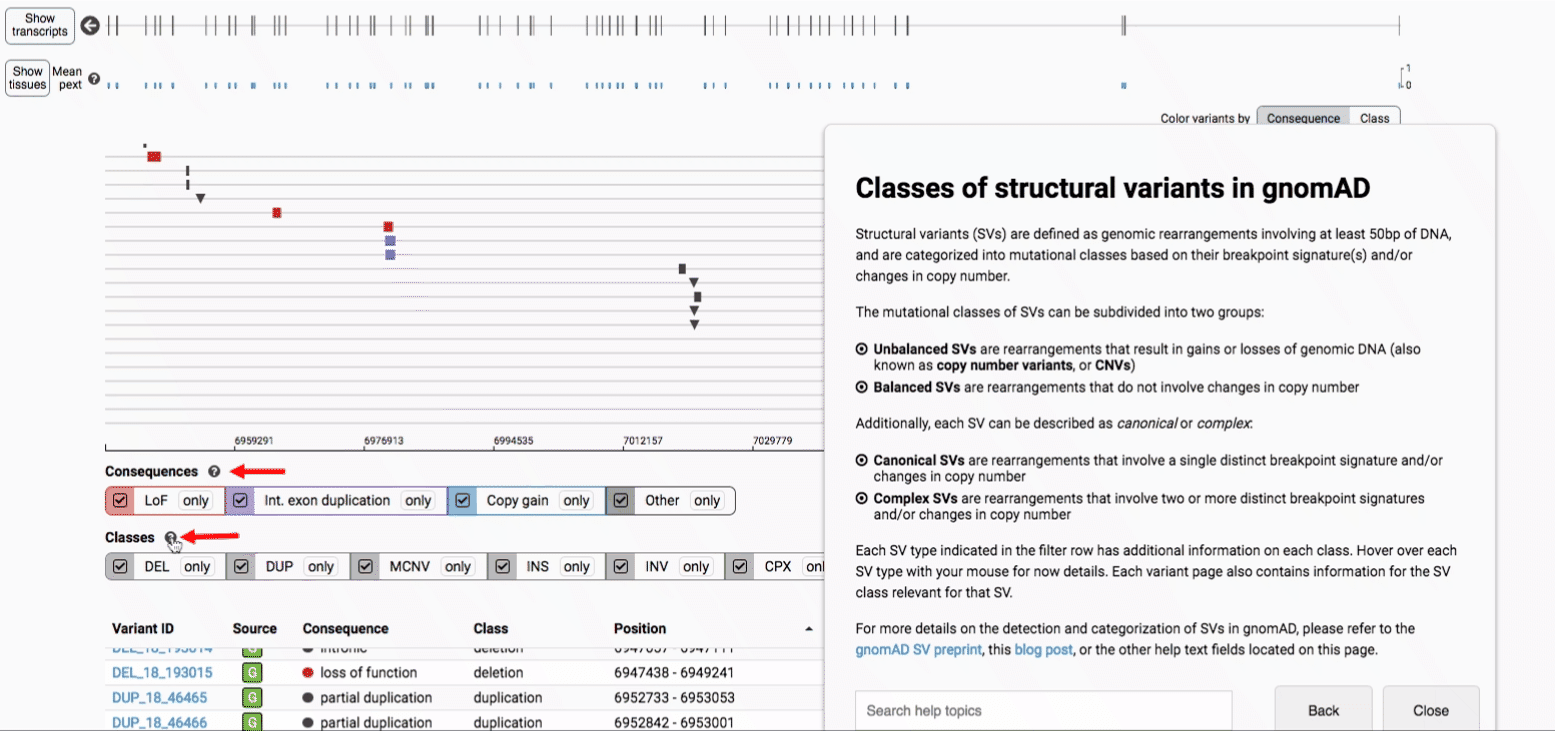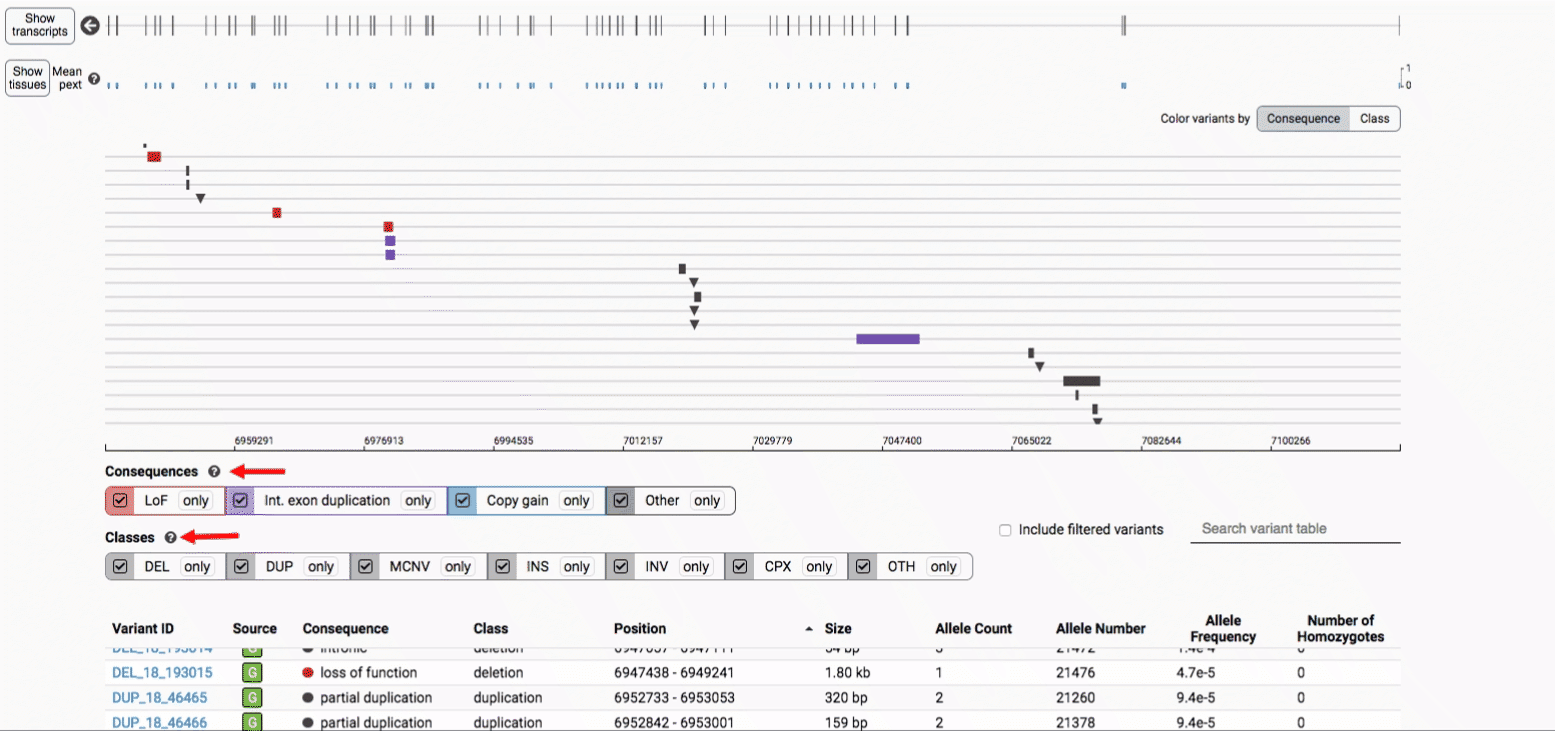
We provide two options for coloring the SV data: color-by-consequence and color-by-class. You can toggle between these modes using the button directly above the variant track on the right side of the page. The current color key will be reflected by the colors used for the two sets of filter buttons found directly below the variant track.
By default, low-quality variants–such as unresolved breakends–will not be displayed in the variant track or table. You can activate these variants using the checkbox labeled “Include filtered variants” directly above the variant table.
Both the variant track and table are synchronized: any filter, sort, scroll, or highlight applied to one will synchronously be applied to the other. For example, hovering over a single row in the variant table will draw a dashed box to highlighting that SV in the table, but will also highlight that same variant and its position in the track (and vice versa).
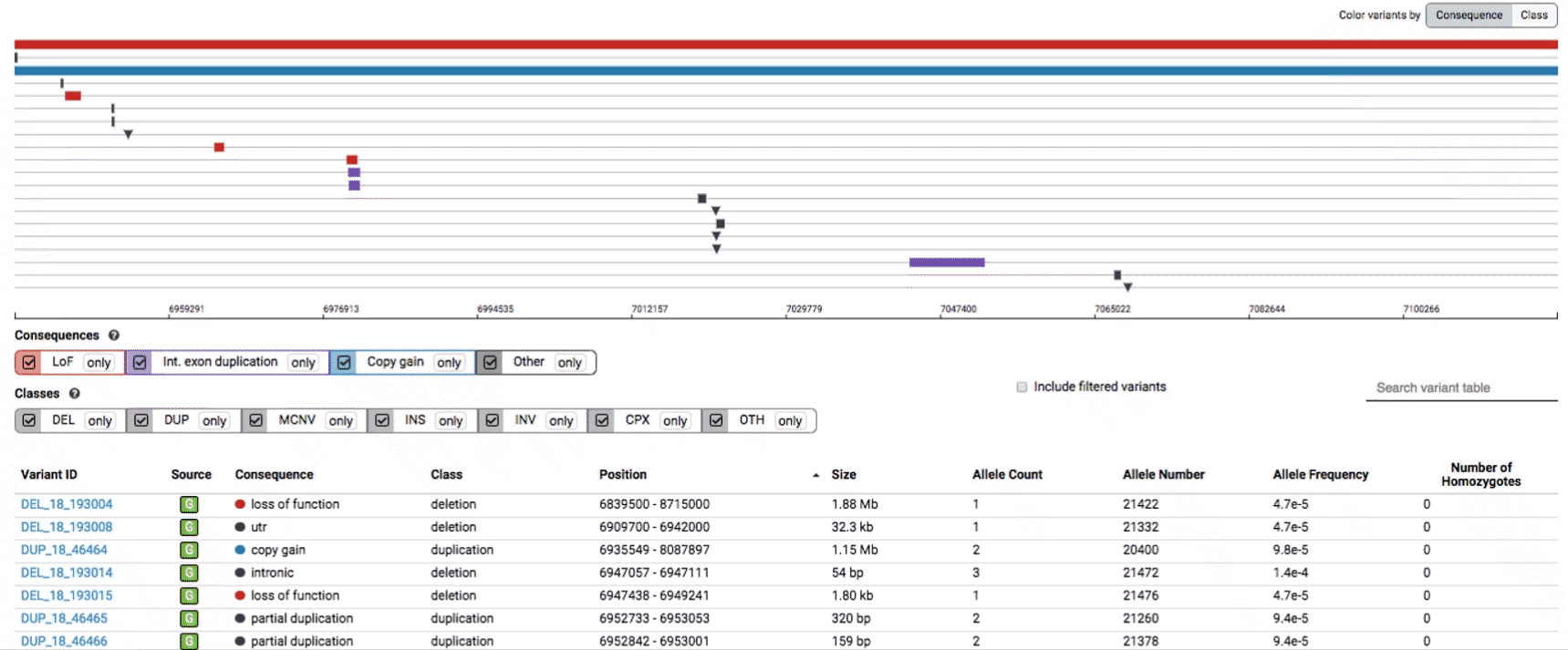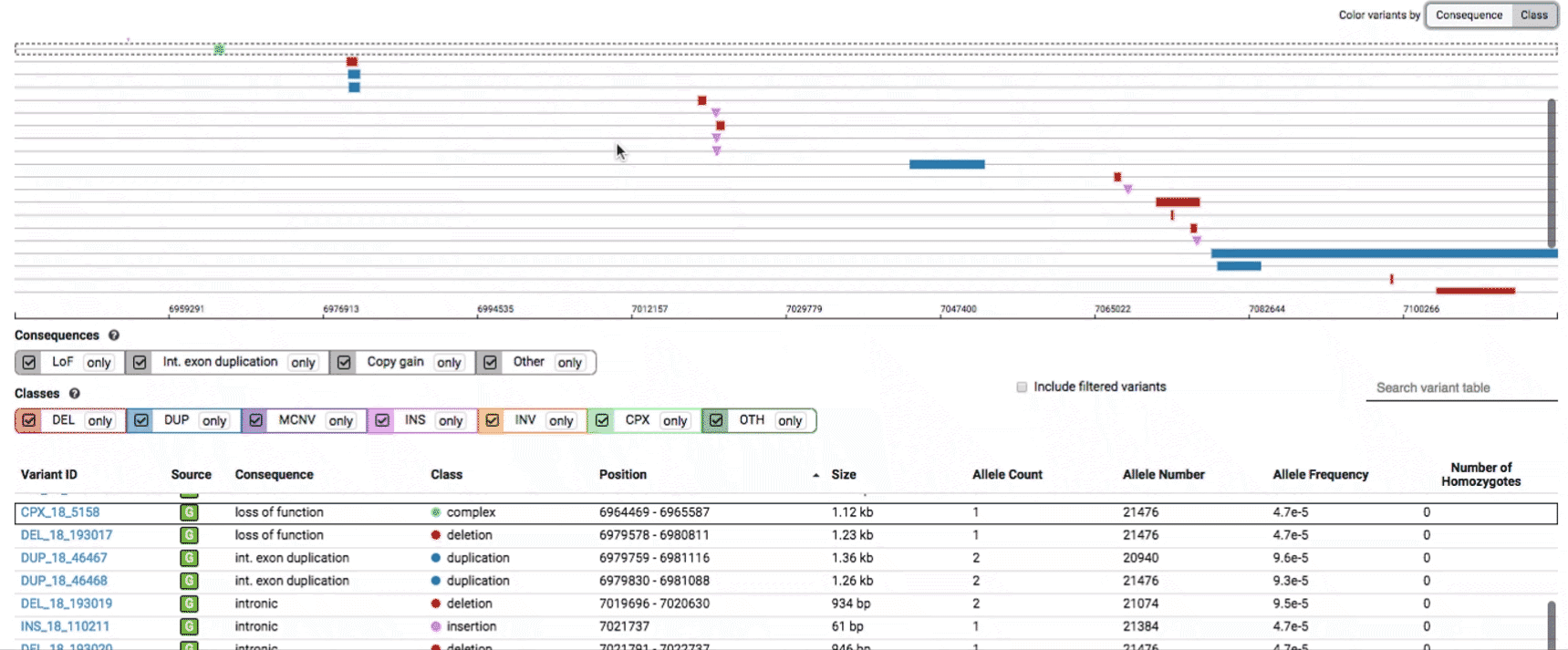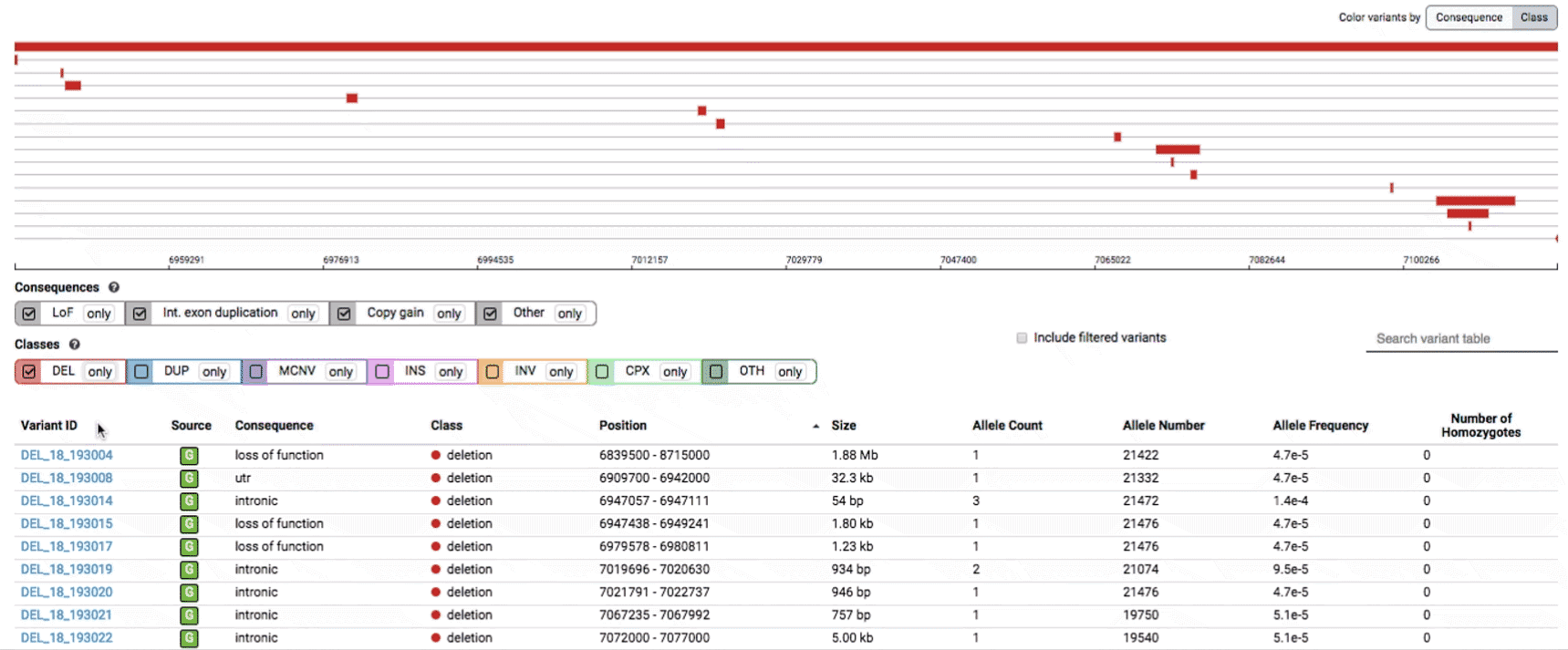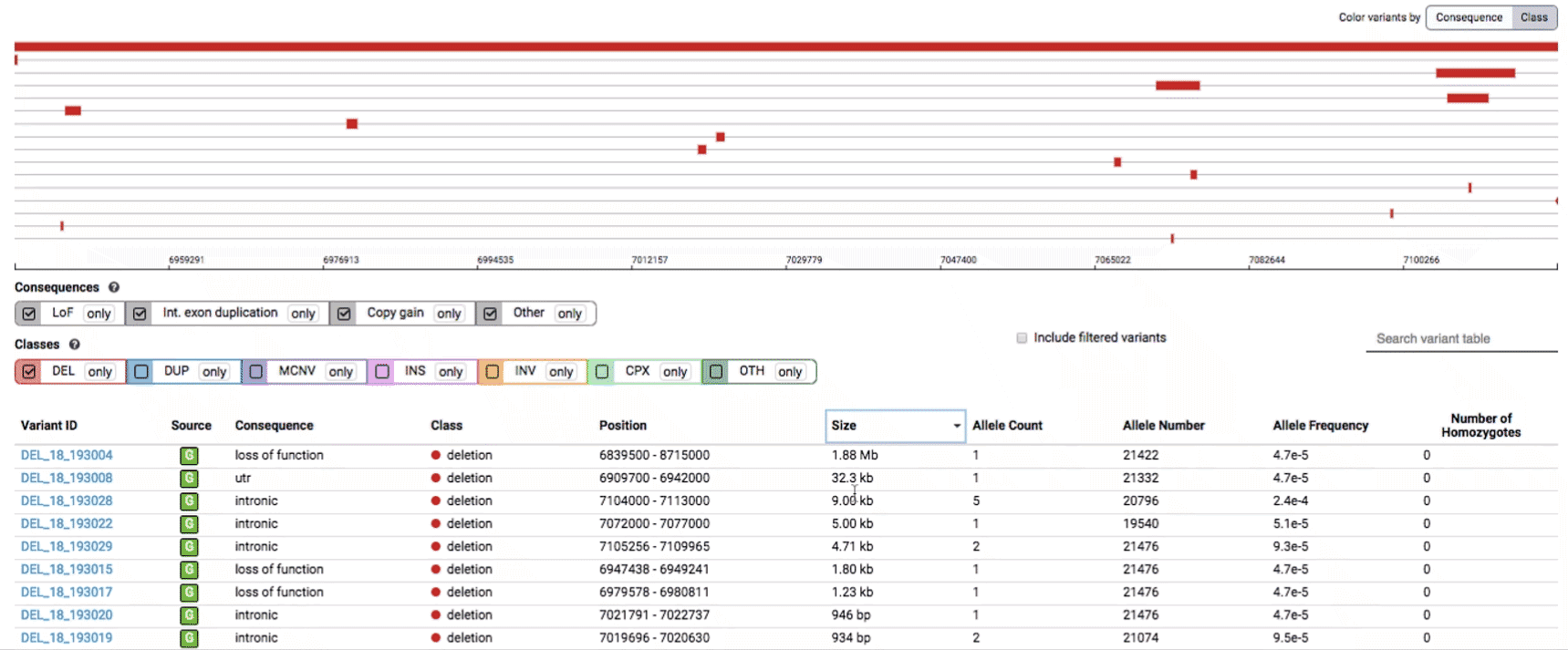
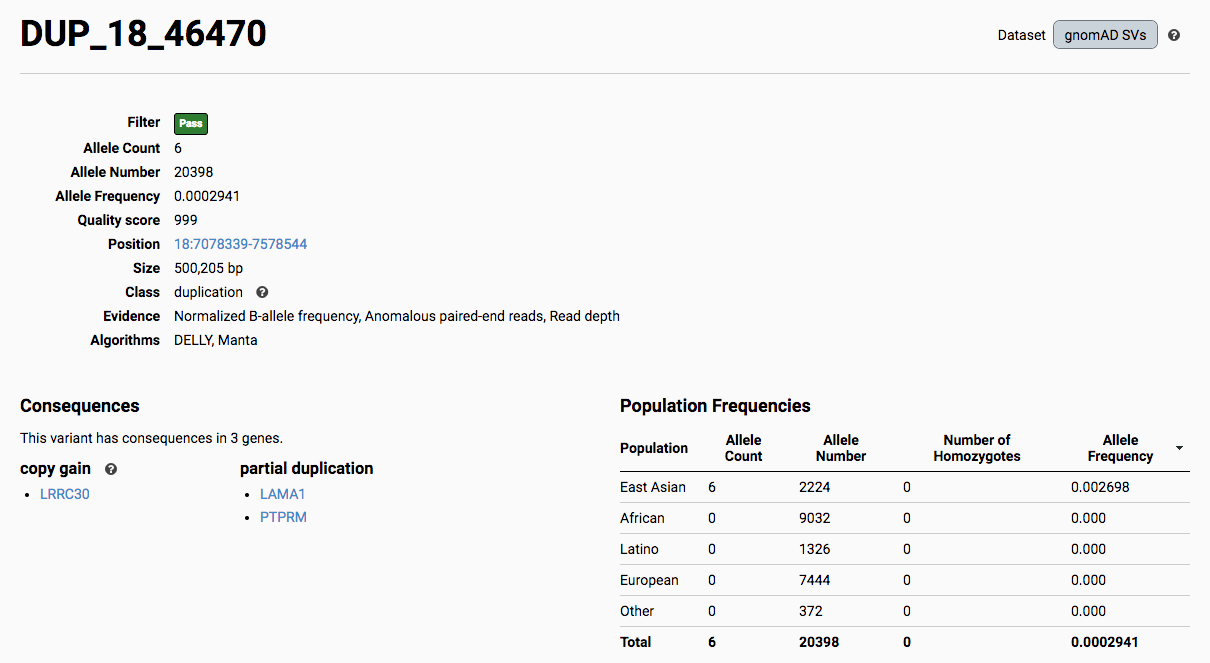
To find more information about an individual variant, you can click on the variant ID in the table or on the variant itself in the track to access the variant page. This page features additional details on the variant, including which algorithms and evidence types contributed to its discovery, its allele frequencies across continental populations, and a full list of all predicted genic consequences.
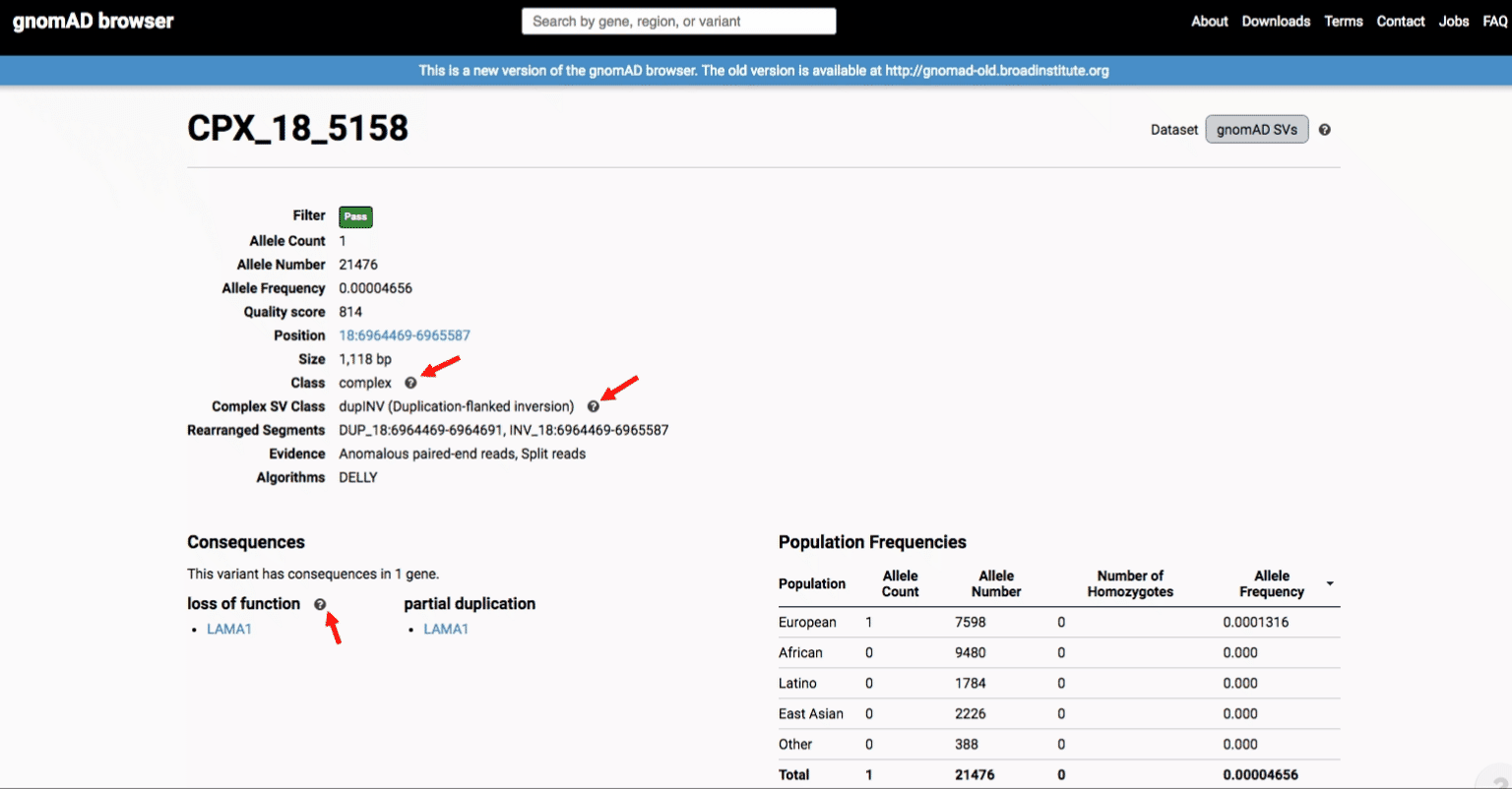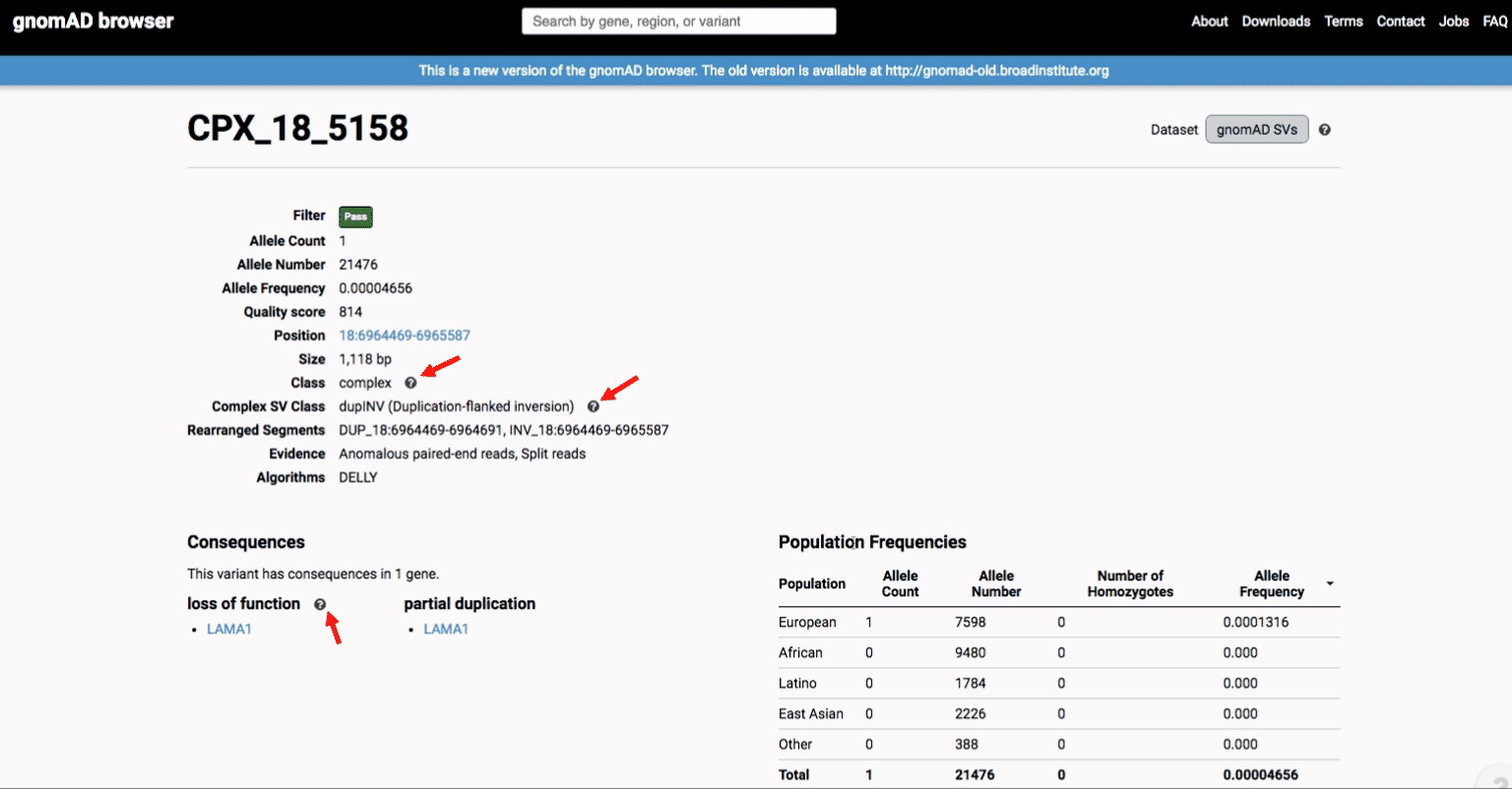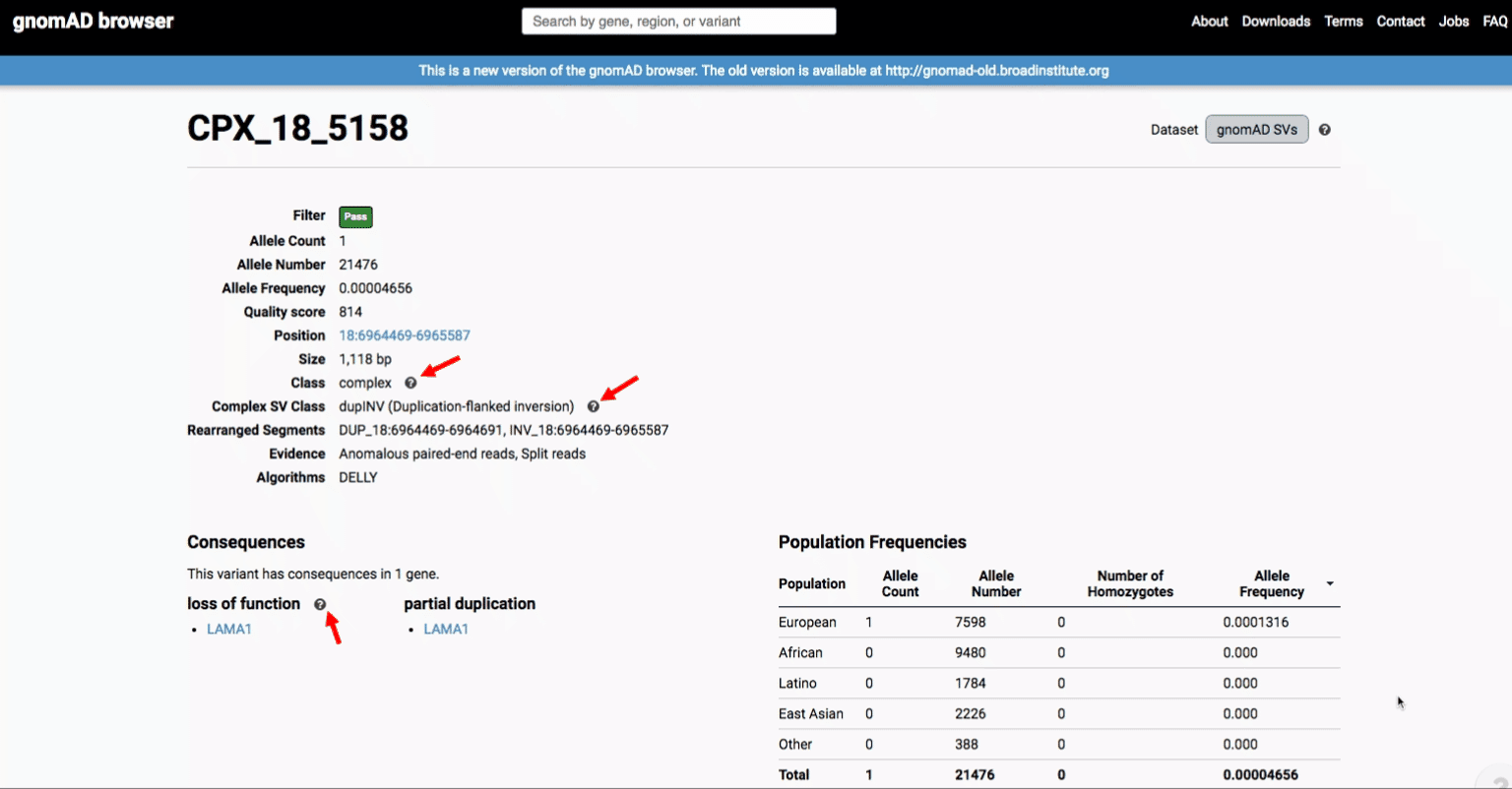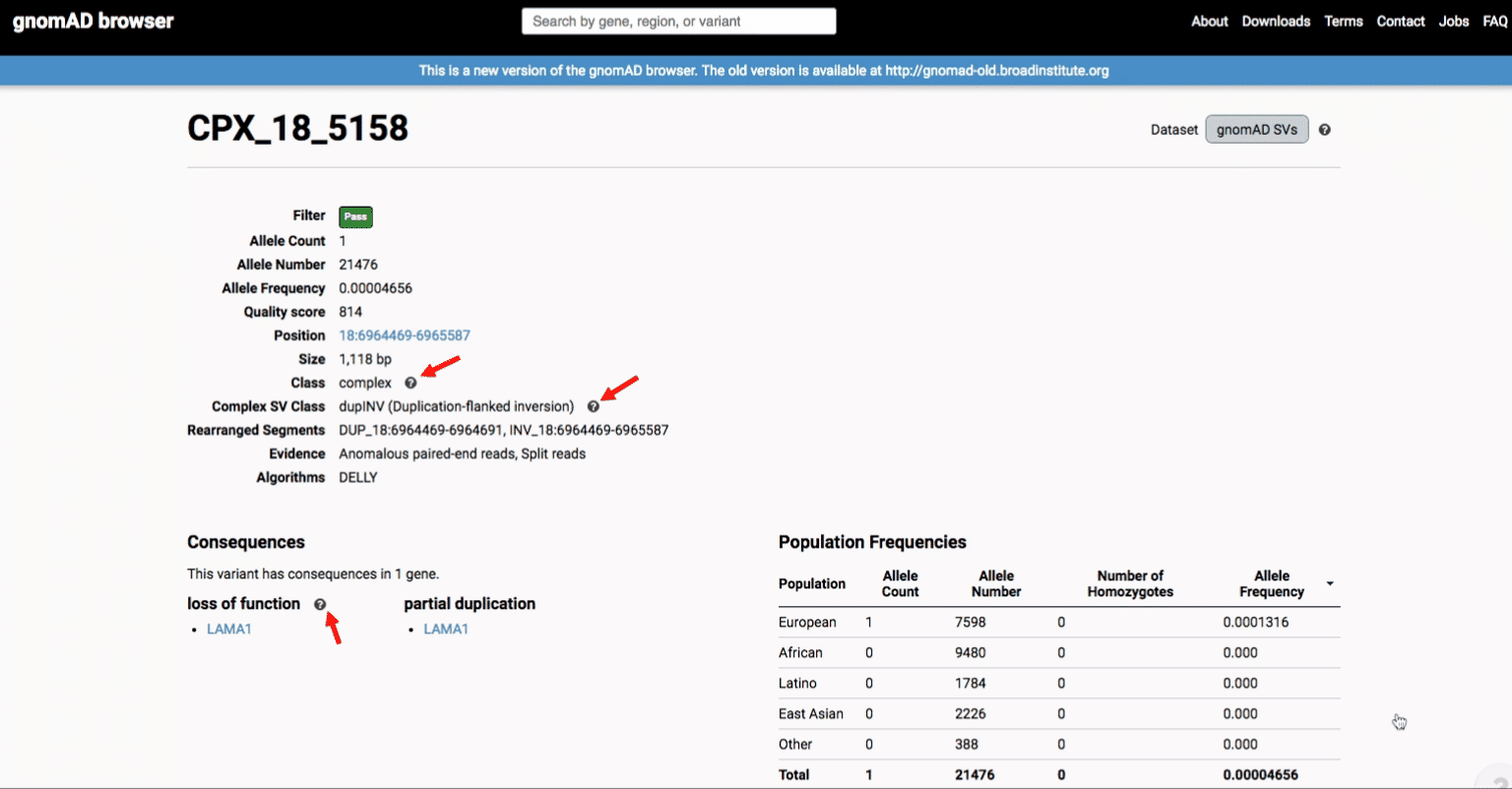
If you’re ever unsure about what a given SV represents or what its functional consequences mean, visit that variant’s page and click on any of the “?” help buttons for more information. This is particularly useful for complex SVs, where each help popup gives a graphical representation of the alternate allele structure.
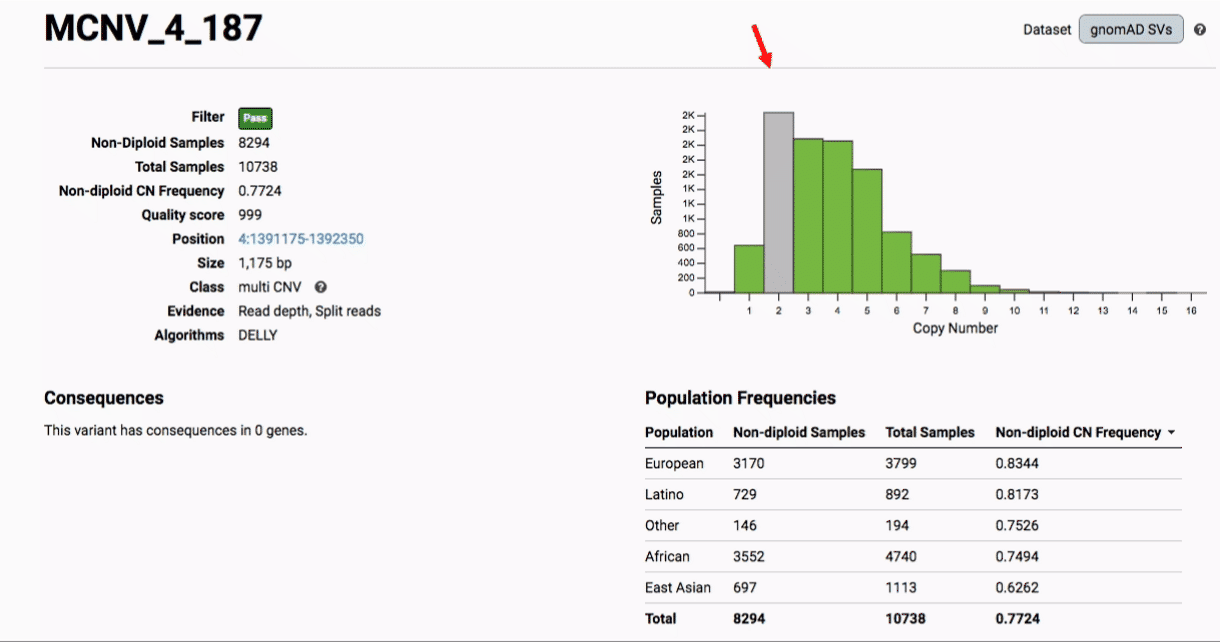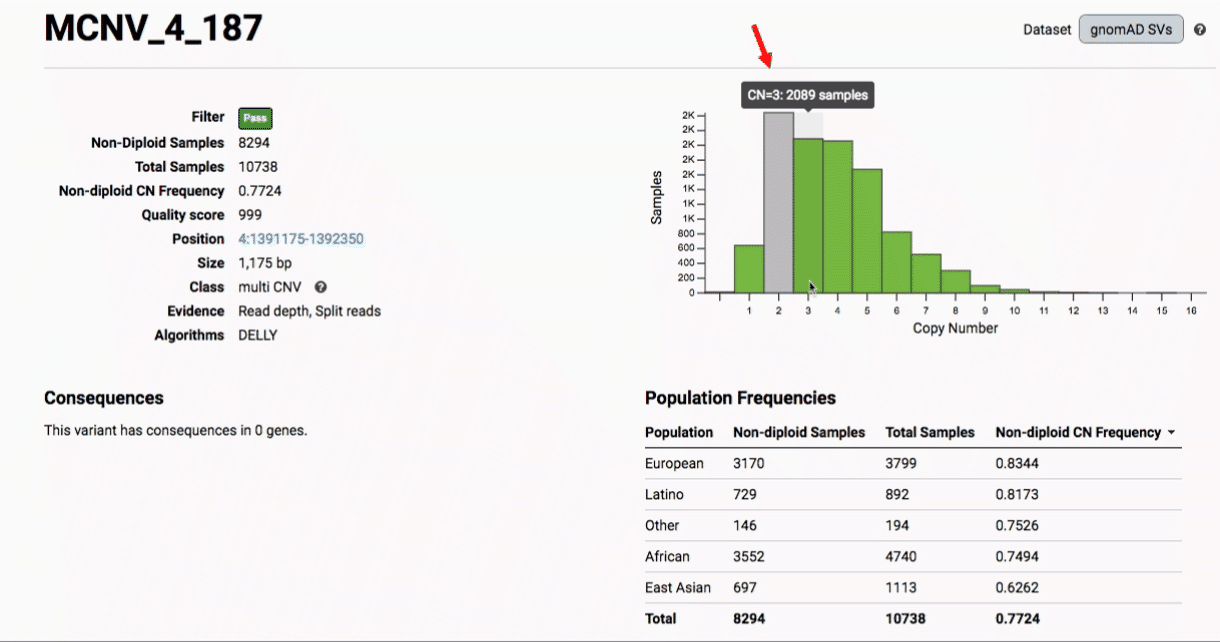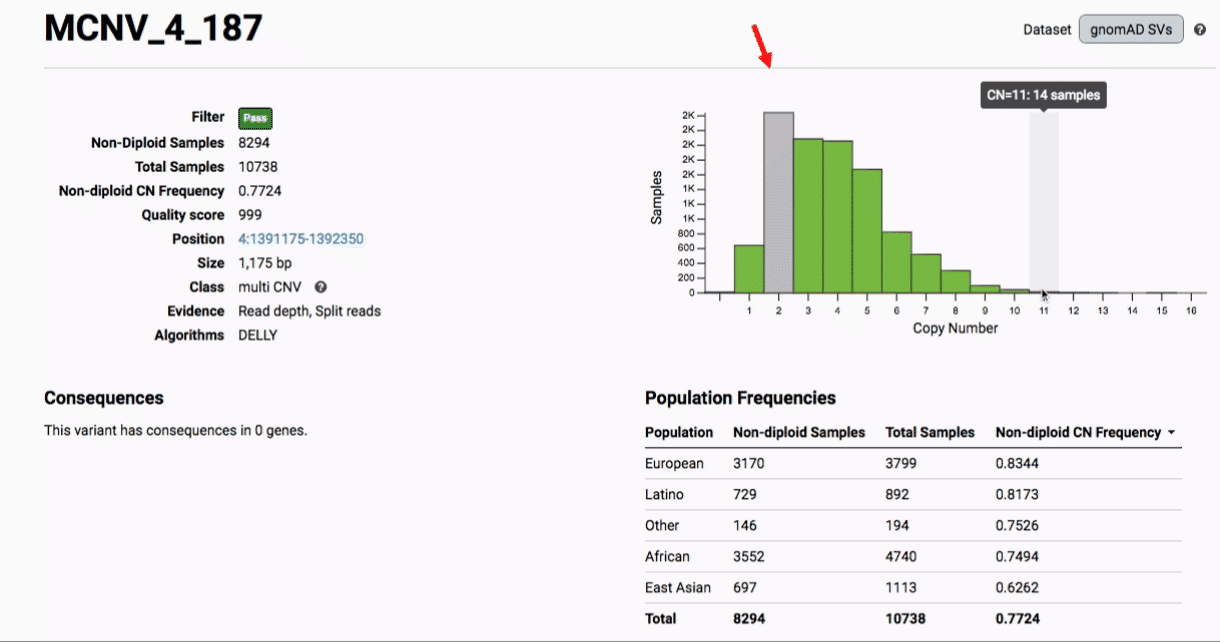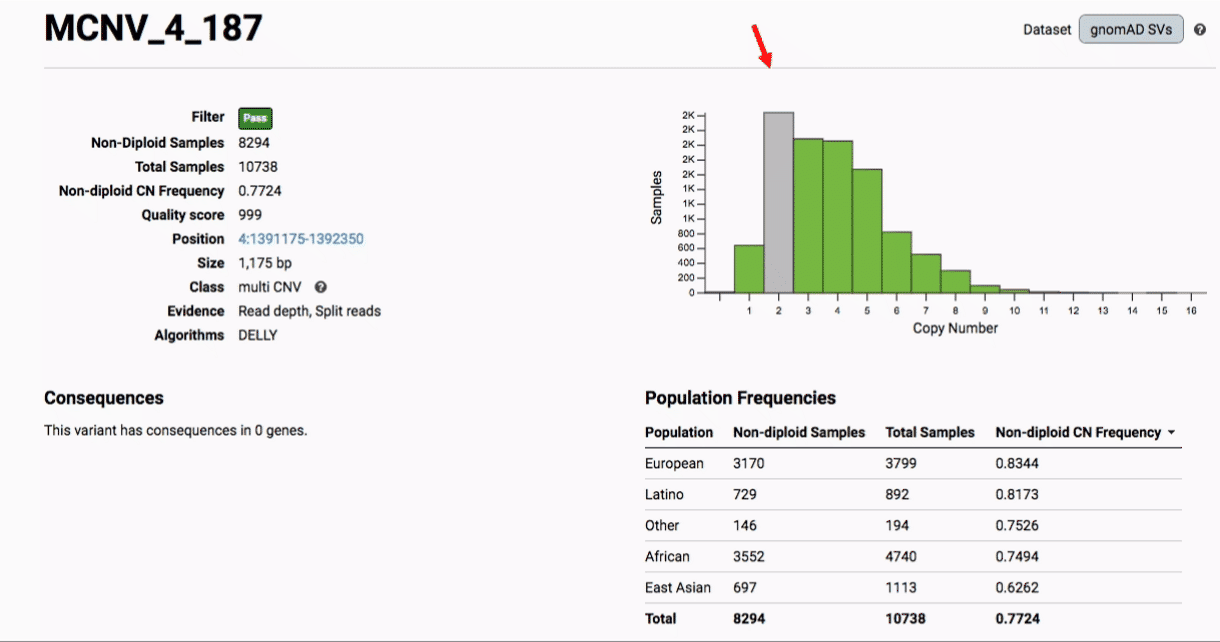
Multiallelic CNVs, which are sites in the genome that have a variable range of copy numbers across individuals in the population, have an extra feature for their variant pages: the distribution of copy numbers in the gnomAD-SV cohort. While we do not phase these regions and/or resolve their individual underlying copy number haplotypes, we provide an aggregate copy number for that locus in sum across both chromosomes per individual. This is represented as a histogram, which has a mouse-over tooltip to show how many individuals are present at each copy state.
Practical considerations when using the gnomAD-SV callset
Below, we list a few important rules-of-thumb to keep in mind when using the gnomAD-SV callset:
- Breakpoint resolution is variable: the resolution of breakpoints varies by the type(s) of evidence contributing to the call, which are marked in the INFO field of the VCF and displayed in the gnomAD browser. Broadly, this means:
- Variants with split read evidence are accurate within ~tens of bases
- Variants with discordant read-pair evidence (but no split read evidence) are accurate within ~tens-to-hundreds of bases
- Variants with read depth evidence (but no split read or read-pair evidence) are accurate within ~hundreds of bases
- Other algorithms and technologies may capture variants missed by gnomAD: although short-read WGS is capable of detecting a broad spectrum of SV classes, it has notable limitations compared to long-read WGS and other approaches. Furthermore, while the four algorithms (Manta, DELLY, MELT, and cn.MOPS) capture a significant fraction of SVs accessible to short-read WGS by comparison to most previous studies, they will certainly not capture all SVs (for instance, small [<300bp] duplications are a known limitation of the current gnomAD callset). Primary sequence context is the most important factor to consider when evaluating SVs ascertained by short-read WGS (such as the data used to build gnomAD-SV). For instance, short-read WGS has limited sensitivity to detect SVs in regions of low-complexity and highly repetitive sequence by comparison to technologies like long-read WGS (i.e., PacBio, Nanopore), optical mapping, or linked-read WGS. In practice, we find short-read WGS performs poorest in regions of segmental duplication (also known as low-copy repeats) or simple repeats.
- Gene consequence annotations are predictions: please note that the gene consequence annotations we generated for gnomAD-SV are predictions, and may not always hold true on a site-by-site basis. Further, we are unable to subdivide our gene consequence annotations for SVs into “low-confidence” and “high-confidence” subsets, such as is performed by LOFTEE for SNVs and indels. Thus, we request that you please carefully inspect each putatively functional SV before interpretation, particularly in the context of its exonic overlap and affected transcripts.
- Manual review of all variants has not been conducted: given the size of this dataset, it is not feasible to curate each variant call. Thus, it is expected that some SVs included in this release represent false and/or misrepresented variant calls, consistent with the range of error rate estimates reported in the gnomAD-SV preprint (~2-12%; see Supplementary Table 4). If you find a variant that appears to meet these criteria, please report the variant.
gnomAD SV discovery methods
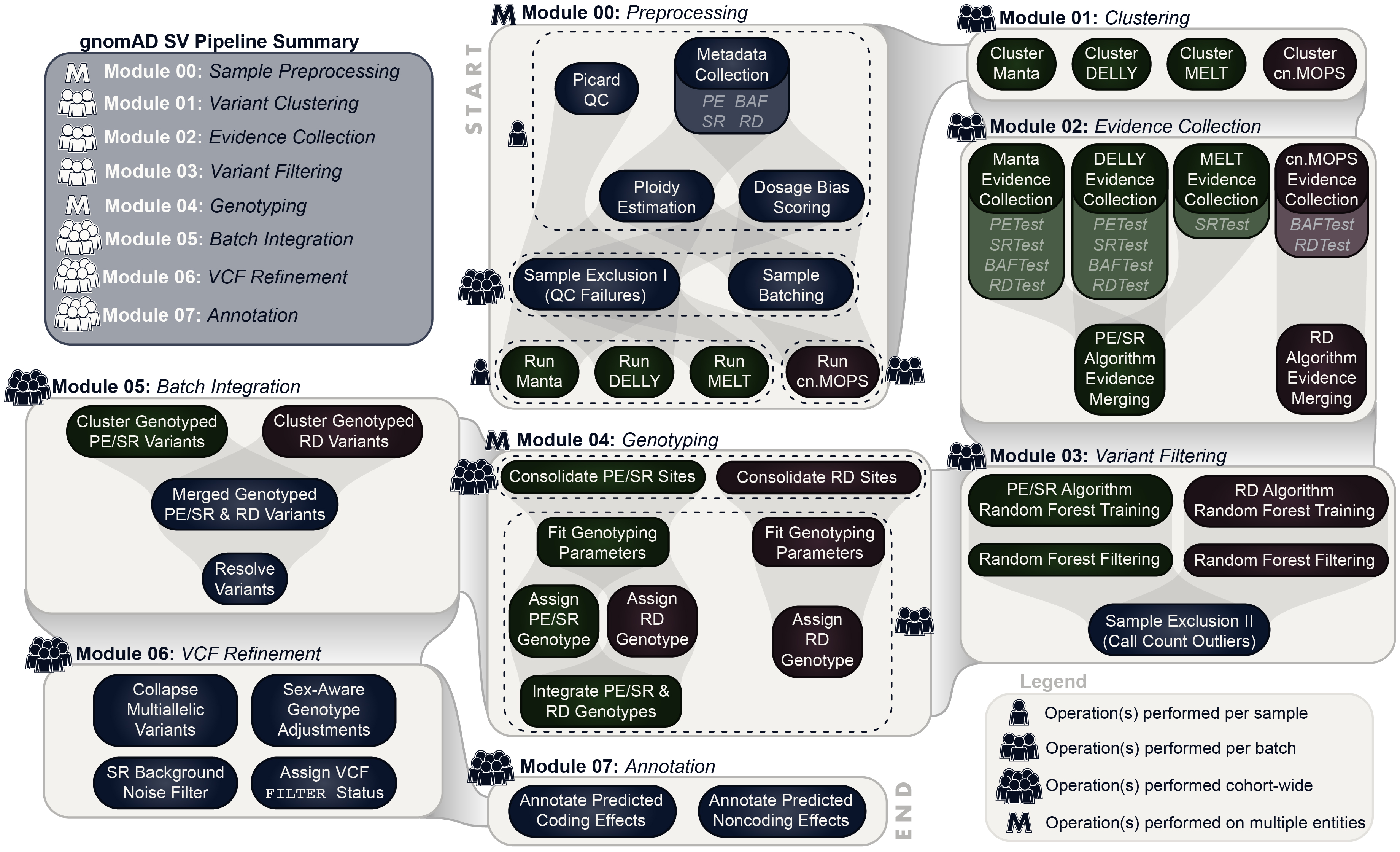
To discover and genotype SVs in this cohort, we extended a multi-algorithm consensus framework from a previous study. You can find technical details on this approach in the methods of Werling et al. (2018) and in the gnomAD-SV preprint.
In this new iteration of the SV pipeline, now dubbed the gnomAD SV Discovery Pipeline, we have configured all methods to be executed on Google Cloud via the Workflow Description Language (WDL) and the Cromwell Execution Engine. For gnomAD-SV, these methods were deployed on FireCloud (now known as Terra), a user-friendly interface for massively parallel computing and managing large bioinformatics workflows in the cloud.
At a high level, the general approach taken by the gnomAD SV Discovery Pipeline can be summarized by the following five steps:
- Executes four independent SV detection algorithms (Manta, DELLY, MELT, and cn.MOPS) per sample
- Integrates raw outputs across algorithms and samples
- Filters calls based on four classes of direct evidence available from raw WGS data (anomalous paired-end reads, read depth, split reads, and B-allele SNP frequencies)
- Genotypes all candidate breakpoints across all samples
- Resolves complex SVs, compound heterozygous sites, multiallelic CNVs, performs sex-aware allosome genotype adjustment, and many more steps to refine variant calls
We have provided all components of this pipeline as WDLs, which are available via the FireCloud Methods Repository. Additional details on code availability can be found in the gnomAD-SV supplement.
For the SV callset described in the gnomAD-SV preprint and the callset released via the gnomAD Browser, we performed extensive QC, applied a series of additional filters, and conducted multiple benchmarking analyses. You can read more about the process of producing the gnomAD-SV callset in the supplement of the gnomAD-SV preprint.
Acknowledgements
The creation of gnomAD-SV would not have been possible without the PIs, researchers, and participants of each study that contributed data towards this overall aggregation effort. We would also like to thank the members of the Talkowski Laboratory, the MacArthur Laboratory, the Analytical and Translational Genetics Unit (ATGU) at MGH, and the Broad-SV Group, all of whom provided valuable insight and feedback throughout the process. Specifically, we are grateful to Nick Watts and Matt Solomonson, who developed the new SV features for the gnomAD Browser. Additional acknowledgements, including grants and grant numbers, are listed in the gnomAD-SV preprint.

Hi,
Thank you for the wonderful resource and explanation of the various files. I can not find how many individuals was included in each of the subsets [B] and [C] that Ryan described above.
Thanks,
Ksenia
LikeLike
Hi Ryan
I have genotyped 20 SNPs and trying to perform an allele frequency comparison between populations. It would be great if I could also get allele information for the sub-populations included in each major population in gnomAD. Is there a way I could find it?
Hope the question is clear enough.
Thank you in advance.
Nomcebo
LikeLike
hi, congratulations for all the hard work! this is a fantastic resource.
I found this variant with an allele frequency above 1:
https://gnomad.broadinstitute.org/variant/INS_X_115404?dataset=gnomad_sv_r2_1
where allele counts are larger than allele numbers. How is this possible?
thanks!!
robert.
LikeLike
Hi Robert,
Thanks for bringing this variant to our attention. Allele number should never be greater than allele count, so we will get to the bottom of what’s going on with this variant and let you know.
Thanks, Ryan
>
LikeLike
Hi Ryan, thanks for looking at this, I guess you mean the other way around that allele count (AC) should never be greater than allele number (AN). Just in case this helps, in the VCF available at
https://storage.googleapis.com/gnomad-public/papers/2019-sv/gnomad_v2.1_sv.sites.vcf.gz
I see the following variants with this problem:
INS_X_115404 X 8946489 8946489 1.09099 16751 15354
BND_X_58404 X 16428221 16428221 1.12409 770 685
DEL_X_185572 X 33889913 33889913
1.22890 859 699DEL_X_186407 X 55702379 55702379
1.26276 495 392INS_X_118344 X 144419590 144419590 1.01675 16385 16115
BND_X_60164 X 154871065 154871065 1.21105 614 507
DUP_Y_54824 Y 9976000 9976000 1.46099 206 141
DUP_Y_54827 Y 13203995 13203995 1.75309 142 81
DUP_Y_54837 Y 13513000 13513000 1.21400 6677 5500
DUP_Y_54838 Y 13535000 13535000 1.01581 5525 5439
DUP_Y_54839 Y 13540000 13540000 1.05316 5725 5436
DUP_Y_54962 Y 22239500 22239500 1.00272 5523 5508
DUP_Y_54964 Y 22242527 22242527 1.01854 5603 5501
DUP_Y_54965 Y 22243145 22243145 1.19211 6559 5502
DUP_Y_54972 Y 22287469 22287469 1.22407 6763 5525
DUP_Y_54973 Y 22287540 22287540 1.10838 6126 5527
DUP_Y_54979 Y 22302849 22302849 1.06983 5914 5528
DUP_Y_54986 Y 22366193 22366193 1.96255 10849 5528
DUP_Y_54988 Y 22422280 22422280 1.95731 10820 5528
DUP_Y_54991 Y 22437287 22437287 1.27618 6922 5424
DUP_Y_54992 Y 22438061 22438061 1.48613 8196 5515
DUP_Y_54998 Y 22443496 22443496 1.74272 9632 5527
Best,
robert.
LikeLike
Hi Robert,
Good catch, and my apologies for the typo: I meant that AC should never be greater than AN.
I can confirm that I also see the issue on our side for these 22 variants, but can’t identify any common failure modes.
My suspicion is these are edge cases where something went awry with our frequency annotation while accounting for sex chromosome ploidy, and we will be sure to correct these in a future release.
For now, I would recommend excluding these 22 variants from your analyses.
Thanks, Ryan
>
LikeLike
Hi Ryan,
Could you please explain what is allele frequency and how to calculate it? I couldn’t figure it out after reading the publications.
And the download file (SV 2.1 sites BED) contains 387,477 variants, it’s either 382,460 nor 433,371(reported in paper), does it right?
Best regards,
Raven
LikeLike
Hi Raven,
Allele frequency for structural variants is the same as for SNVs & indels: it’s the number of total chromosomes in the population that carry the alternate allele. It’s computed from the VCF as AC / AN.
Regarding the number of variants in the VCF: there was a small subset of samples in gnomAD-SV (n=1,806) that weren’t appropriately consented for public release of their genetic data, so these samples were removed prior to release of the VCF. This is why the count of variants in the public VCF doesn’t match the counts listed in the paper. If you’re curious, the breakdown of samples at various stages is provided in Supplementary Tables 1-2 of the gnomAD-SV paper.
Thanks,
Ryan
LikeLike
Hi Raven,
Thank you so much for your reply!
So it means that for each genome the AN equals 2, the AC of individual variant equals 1 means only one chromosome carry this variant and the AC equals 2 means it is homozygous?
Best,
Raven
LikeLike
Hi Raven,
Yes, exactly—your interpretation is correct. We also provide N_HET and N_HOMALT fields in the downloadable VCF and BED files if you’re interested in the number of heterozygous or homozygous carriers, respectively.
Thanks,
Ryan
LikeLike
Hi Ryan,
I also noticed different allele number for different structural variants in the browser. How gnomAD determined the AN for individual variants? Thanks!
Best,
Raven
LikeLike
Hi Raven,
AN differs across variants due to how we handle low-quality individual genotypes.
If you’re curious, the specifics of this filtering is described in the supplementary methods of the gnomAD-SV paper, but in essence we discard genotypes with low quality scores and count them neither towards AC nor AN.
Sites with lower AN will indicate that more samples had low-quality genotypes, and thus might also indicate that the variant was technically more challenging to genotype.
Thanks, Ryan
>
LikeLike
Hi Ryan,
Please could you advise whether SV 2.1 sites release is based on hg38 genome build?
Thanks for your help!
LikeLike
Hi,
The current (v2.1) gnomAD SV release is native to hg19, although NCBI dbVar is maintaining a hg38 liftOver equivalent of the v2.1 SV callset under accession number nstd166, here:
https://www.ncbi.nlm.nih.gov/sites/dbvarapp/studies/nstd166/
Hope this helps!
Thanks,
Ryan
LikeLike
Hi all,
nice resource!! Sorry for my question, but where I can find the description about what does it mean the different files of SV founded in download part of gnomad web page?? for example:
SV 2.1 sites VCF
SV 2.1 (controls) sites VCF
SV 2.1 (non-neuro) sites VCF
Thanks for your help!
LikeLike
Hi Jordi,
As of the version 2.1 SV release, we are now providing VCF subsets corresponding to different sample filtering criteria, consistent with the short variant (SNV/indel) releases.
The general structure of the “controls-only” and “non-neuro” subsets can be found in the first paragraph of this post: https://macarthurlab.org/2018/10/17/gnomad-v2-1/
But just to summarize:
A. SV 2.1 sites VCF: includes SVs from all unrelated samples for which we are permitted to release aggregated site-frequency data
B. SV 2.1 (controls) sites VCF: as above in [A], but restricted to samples explicitly labeled as healthy “control” samples by their contributing studies
C. SV 2.1 (non-neuro) sites VCF: as above in [A], but after excluding samples with a known neuropsychiatric disease diagnosis.
So the variants found in B & C will be strict subsets of A.
Hope this helps,
Ryan
LikeLike